KI Prognose: Wahrscheinlichkeiten verstehen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Wer sich mit KI-gestützten Fußballprognosen beschäftigt, stößt früher oder später auf einen grundlegenden Unterschied in der Art, wie Vorhersagen formuliert werden. Die einen sagen: Bayern München gewinnt. Die anderen sagen: Bayern München gewinnt mit 65 Prozent Wahrscheinlichkeit. Dieser Unterschied mag auf den ersten Blick wie eine Nebensächlichkeit erscheinen, doch er verändert fundamental, wie wir über Prognosen nachdenken sollten.
Die probabilistische Herangehensweise, also die Arbeit mit Wahrscheinlichkeiten statt fester Aussagen, hat sich in der modernen Sportanalyse durchgesetzt. Minimiere dein Risiko durch eine mathematisch fundierte AI Champions League Vorhersage. Sie ist ehrlicher, nützlicher und wissenschaftlich fundierter als die Tradition der kategorischen Tipps. Gleichzeitig erfordert sie ein Umdenken beim Nutzer, der lernen muss, mit Unsicherheit umzugehen, statt nach Gewissheit zu suchen.
In diesem Artikel geht es um die Welt der wahrscheinlichkeitsbasierten KI-Vorhersagen für die Champions League. Warum sind Prozente besser als einfache Tipps? Wie interpretiert man diese Zahlen richtig? Wie lassen sich Wahrscheinlichkeiten für eigene Analysen nutzen? Und was macht ein gut kalibriertes Prognosemodell aus? Die Antworten auf diese Fragen bilden das Fundament für einen informierten Umgang mit KI-Prognosen.
Warum Wahrscheinlichkeiten besser sind als feste Tipps
Der Reiz eines klaren Tipps ist verständlich. Bayern gewinnt, Dortmund verliert, das Spiel endet unentschieden. Solche Aussagen sind leicht zu verstehen und geben ein Gefühl von Sicherheit. Doch diese Sicherheit ist trügerisch, weil sie die inhärente Unsicherheit des Fußballs ignoriert.
Fußball ist ein Sport mit niedriger Torzahl und hoher Varianz. In einem typischen Spiel fallen zwei bis drei Tore, und oft entscheiden einzelne Szenen über Sieg oder Niederlage. Ein Pfostenschuss, eine strittige Elfmeterentscheidung, ein individueller Fehler. All diese Momente sind nicht vorhersehbar, aber sie bestimmen den Ausgang. Wer behauptet, er wisse sicher, wer gewinnt, unterschätzt diese Komplexität.
Die Wahrscheinlichkeitsangabe dagegen ist ein Eingeständnis von Unsicherheit. Wenn ein Modell sagt, dass Bayern mit 65 Prozent Wahrscheinlichkeit gewinnt, sagt es gleichzeitig, dass Bayern mit 35 Prozent Wahrscheinlichkeit nicht gewinnt. Diese Kehrseite wird oft vergessen, ist aber ebenso wichtig. Die Prognose kommuniziert nicht nur die Erwartung, sondern auch das Ausmaß der Unsicherheit.
Für analytisch denkende Beobachter eröffnet die Wahrscheinlichkeitsangabe zusätzliche Möglichkeiten. Sie ermöglicht den Vergleich mit anderen Einschätzungen, etwa den impliziten Wahrscheinlichkeiten aus Wettquoten. Sie erlaubt die Aggregation mehrerer Prognosen zu einem Gesamtbild. Und sie bildet die Grundlage für systematische Analysen über viele Spiele hinweg.
Der Ehrlichkeitsfaktor spielt ebenfalls eine Rolle. Ein Analyst, der nur mit festen Tipps arbeitet, kann sich hinter Ausreden verstecken, wenn seine Vorhersage nicht eintritt. Es war halt ein unglücklicher Tag, der Schiedsrichter hat schlecht gepfiffen, die Form hat plötzlich eingebrochen. Ein Analyst, der mit Wahrscheinlichkeiten arbeitet, macht sich transparent angreifbar. Seine Prognosen können über viele Spiele hinweg überprüft werden, und die Qualität seiner Arbeit wird messbar.
Die Nutzbarkeit für eigene Entscheidungen ist der vielleicht wichtigste Vorteil. Wer nur weiß, dass Bayern gewinnt, hat wenig Anhaltspunkte für die Frage, wie viel Vertrauen er in diese Aussage setzen sollte. Wer weiß, dass Bayern mit 65 Prozent Wahrscheinlichkeit gewinnt, kann diese Information mit anderen Faktoren abgleichen und eine fundierte Einschätzung entwickeln. Die Wahrscheinlichkeit wird zum Ausgangspunkt eigener Überlegungen, nicht zum Endpunkt.
Wie man KI-Wahrscheinlichkeiten richtig interpretiert
Die korrekte Interpretation von Wahrscheinlichkeiten fällt vielen Menschen schwer, weil unser Gehirn für den Umgang mit Unsicherheit nicht optimiert ist. Wir neigen dazu, hohe Wahrscheinlichkeiten mit Gewissheit gleichzusetzen und niedrige Wahrscheinlichkeiten zu unterschätzen. Diese kognitiven Verzerrungen führen regelmäßig zu Fehleinschätzungen.
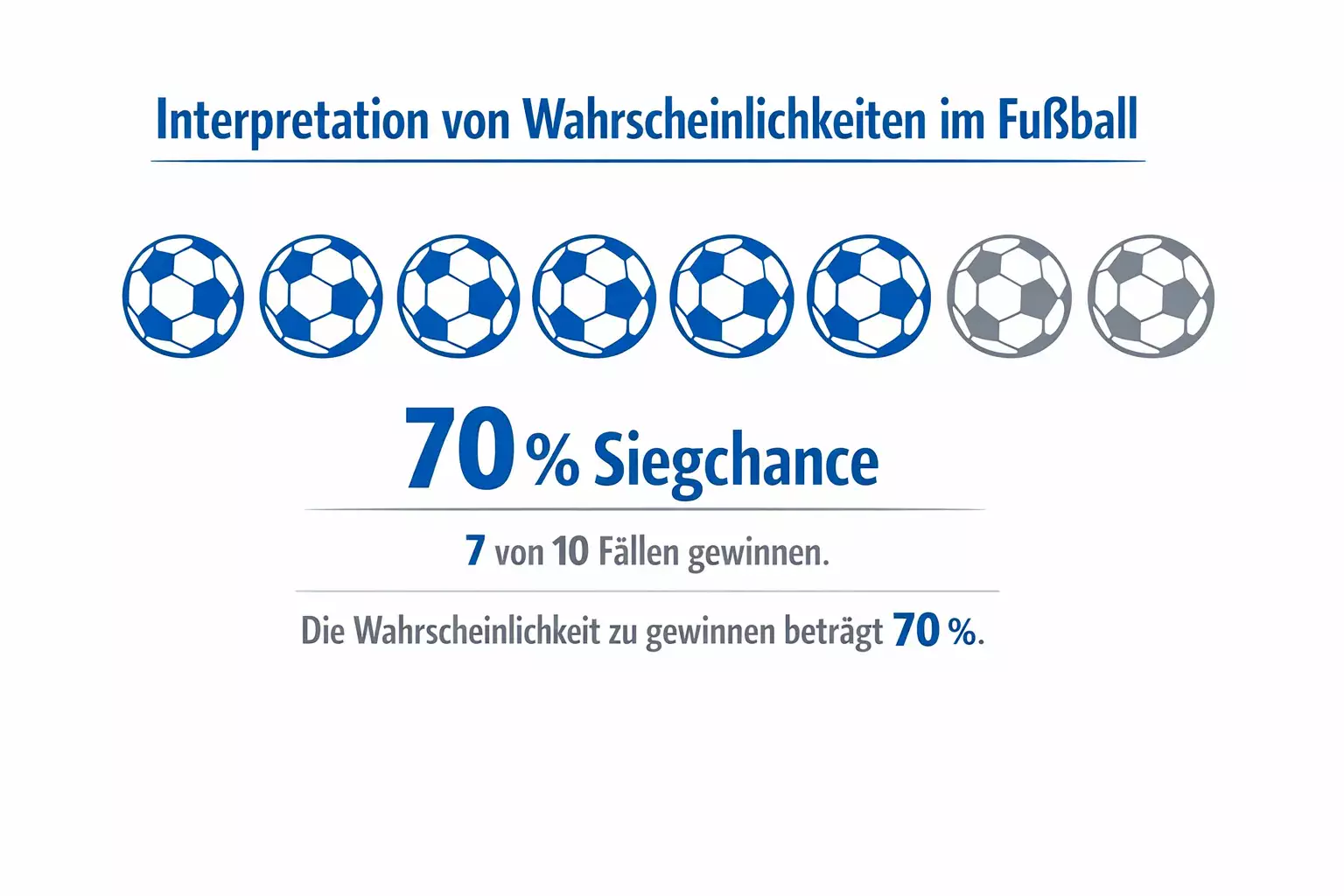
Eine Wahrscheinlichkeit von 70 Prozent für einen Bayern-Sieg bedeutet nicht, dass Bayern sicher gewinnt. Sie bedeutet, dass bei zehn vergleichbaren Spielen Bayern im Durchschnitt sieben gewinnen würde und drei nicht. Das klingt abstrakt, hat aber praktische Konsequenzen. Bei einem einzelnen Spiel ist das Eintreten der unwahrscheinlicheren Variante keine Sensation, sondern eine realistische Möglichkeit.
Der umgekehrte Fall ist ebenso wichtig. Wenn ein Außenseiter mit 15 Prozent Siegwahrscheinlichkeit bewertet wird, bedeutet das nicht, dass ein Sieg dieses Teams unmöglich oder auch nur extrem selten ist. Bei etwa jedem siebten vergleichbaren Spiel würde dieser Außenseiter triumphieren. In einem Wettbewerb wie der Champions League mit vielen Spielen treten solche Überraschungen regelmäßig ein.
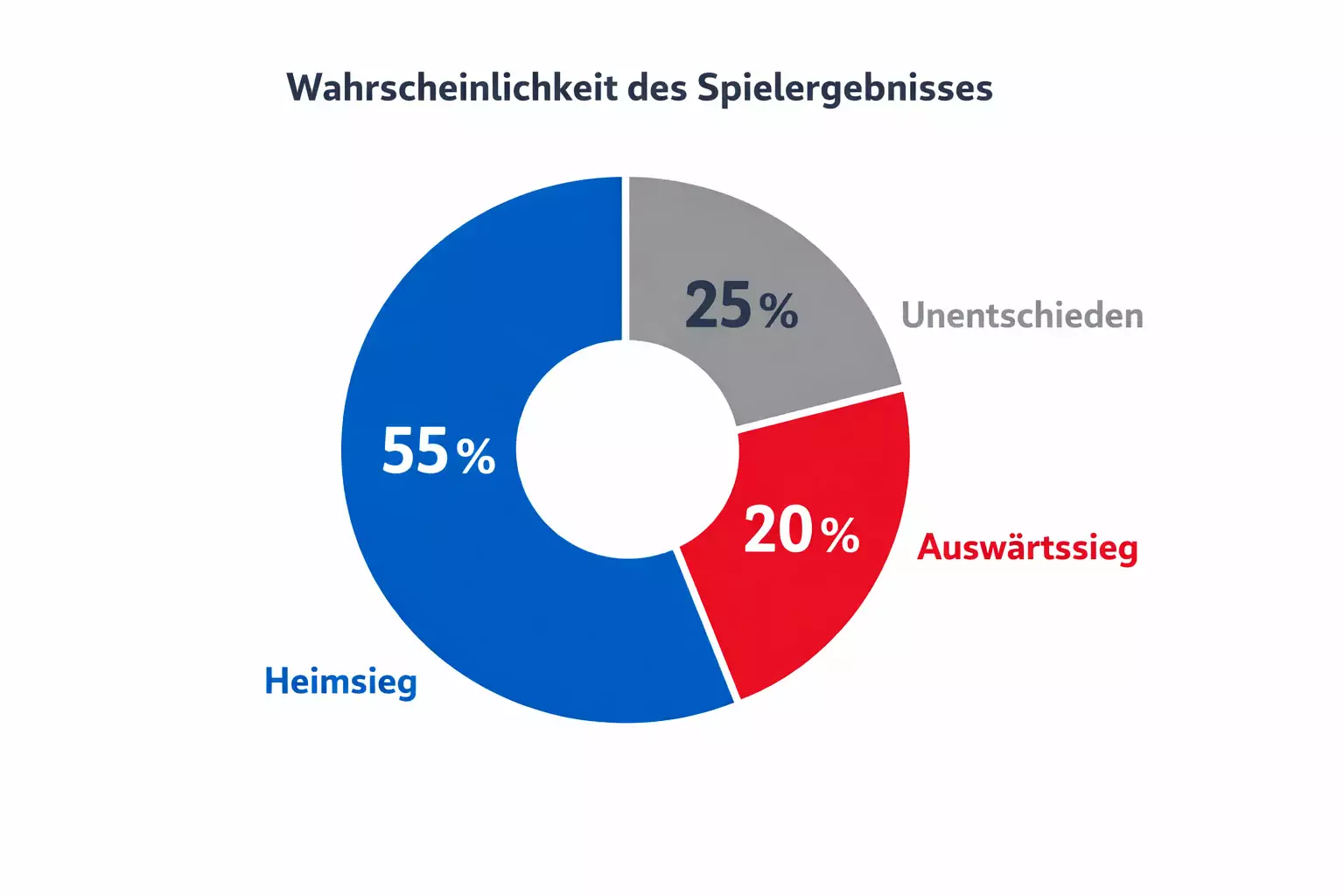
Die Behandlung von Unentschieden verdient besondere Aufmerksamkeit. Im Fußball enden etwa 25 bis 30 Prozent aller Spiele remis, abhängig vom Wettbewerb und der Konstellation. Viele Menschen unterschätzen diese Häufigkeit intuitiv. Ein KI-Modell, das einem Spiel jeweils 40 Prozent Siegwahrscheinlichkeit für beide Teams und 20 Prozent für ein Unentschieden zuweist, prognostiziert ein offenes Spiel mit leichtem Vorteil für beide Teams gegenüber dem Remis. Diese Differenzierung geht bei festen Tipps verloren.
Die zeitliche Dimension von Wahrscheinlichkeiten wird ebenfalls oft missverstanden. Eine Prognose, die drei Tage vor dem Spiel erstellt wird, basiert auf anderen Informationen als eine, die am Spieltag aktualisiert wird. Verletzungsmeldungen, Aufstellungsgerüchte, Wetterbedingungen und andere Faktoren können die Wahrscheinlichkeiten signifikant verschieben. Die Angabe des Zeitpunkts der Prognose ist daher wesentlich für ihre Interpretation.
Ein häufiger Fehler besteht darin, Wahrscheinlichkeiten als präzise Messungen zu behandeln. Wenn ein Modell 62,3 Prozent für einen Heimsieg ausgibt, suggerieren die Nachkommastellen eine Genauigkeit, die in Wirklichkeit nicht existiert. Der Unterschied zwischen 60 und 65 Prozent mag statistisch signifikant sein, der Unterschied zwischen 62 und 63 Prozent ist es meist nicht. Seriöse Prognostiker runden ihre Angaben daher auf fünfer Schritte oder geben Konfidenzintervalle an.
Die Bewertung von Extremwahrscheinlichkeiten erfordert besondere Vorsicht. Wenn ein Modell einer Mannschaft weniger als fünf Prozent Siegchance zuweist oder mehr als 95 Prozent, sollte man skeptisch werden. Solche Extremwerte sind im Fußball selten gerechtfertigt, weil die inhärente Varianz des Spiels immer einen gewissen Bodensatz an Unsicherheit erzeugt. Modelle, die regelmäßig Extremwahrscheinlichkeiten ausgeben, sind oft schlecht kalibriert.
Von Wahrscheinlichkeiten zu Wettentscheidungen
Für viele Nutzer von KI-Prognosen steht die Frage im Raum, wie sich Wahrscheinlichkeiten in konkrete Entscheidungen übersetzen lassen. Im Kontext von Sportwetten bedeutet das: Wie erkenne ich, ob eine Wette lohnenswert ist? Die Antwort liegt im Konzept des Value, das den Vergleich zwischen eigener Einschätzung und Marktquote systematisiert.
Der Grundgedanke ist einfach. Buchmacher drücken ihre Einschätzung eines Spielausgangs durch Quoten aus. Diese Quoten lassen sich in implizite Wahrscheinlichkeiten umrechnen. Eine Quote von 2,00 entspricht einer impliziten Wahrscheinlichkeit von 50 Prozent, eine Quote von 4,00 entspricht 25 Prozent. Wenn die eigene Einschätzung der Wahrscheinlichkeit höher liegt als die implizite Quote, spricht man von einer Value-Wette.
Ein Beispiel verdeutlicht das Prinzip. Angenommen, ein KI-Modell bewertet die Siegchance von Arsenal mit 60 Prozent. Der Buchmacher bietet eine Quote von 1,80 für diesen Ausgang, was einer impliziten Wahrscheinlichkeit von etwa 55,6 Prozent entspricht. Die Differenz zwischen der eigenen Einschätzung und der Markteinschätzung beträgt knapp fünf Prozentpunkte zugunsten der eigenen Prognose. Dies deutet auf Value hin.
Die mathematische Formalisierung dieses Konzepts führt zum Erwartungswert. Der Erwartungswert einer Wette errechnet sich aus der Wahrscheinlichkeit des Gewinns multipliziert mit dem Nettogewinn abzüglich der Wahrscheinlichkeit des Verlusts multipliziert mit dem Einsatz. Ist der Erwartungswert positiv, ist die Wette langfristig profitabel, unabhängig vom Ausgang des einzelnen Spiels. Im obigen Beispiel wäre der Erwartungswert positiv, weil die eigene Wahrscheinlichkeitsschätzung über der impliziten Marktwahrscheinlichkeit liegt.

Das Kelly-Kriterium geht einen Schritt weiter und beantwortet die Frage, wie viel vom verfügbaren Budget auf eine Value-Wette gesetzt werden sollte. Die Formel berücksichtigt sowohl die Größe des vermuteten Vorteils als auch das Risiko und optimiert das langfristige Kapitalwachstum. Sie lautet vereinfacht: Einsatzanteil gleich Gewinnwahrscheinlichkeit mal Quote minus eins, geteilt durch Quote minus eins.
Für das Arsenal-Beispiel mit 60 Prozent Eigenwahrscheinlichkeit und Quote 1,80 ergibt sich: 0,60 mal 1,80 minus 1, geteilt durch 0,80, was etwa 0,10 oder 10 Prozent entspricht. Nach dem Kelly-Kriterium wäre ein Einsatz von 10 Prozent des verfügbaren Budgets optimal.
In der Praxis empfehlen viele Experten allerdings das fraktionelle Kelly-System. Dabei wird nur ein Bruchteil des berechneten Einsatzes gespielt, typischerweise die Hälfte oder ein Viertel. Der Grund liegt in der Unsicherheit der eigenen Wahrscheinlichkeitsschätzung. Wenn die KI-Prognose nicht perfekt kalibriert ist, und das ist sie nie, können volle Kelly-Einsätze zu großen Schwankungen führen. Das Half-Kelly oder Quarter-Kelly reduziert dieses Risiko erheblich.
Ein kritischer Punkt ist die Qualität der eigenen Wahrscheinlichkeitsschätzung. Die gesamte Value-Berechnung steht und fällt mit der Annahme, dass die eigene Einschätzung näher an der Wahrheit liegt als die des Marktes. Das ist keineswegs selbstverständlich. Buchmacher beschäftigen Teams von Analysten und nutzen selbst KI-Modelle. Wer glaubt, er könne den Markt systematisch schlagen, sollte seine Prognosen über einen längeren Zeitraum dokumentieren und auf Kalibrierung prüfen.
Die Kalibrierung von KI-Systemen
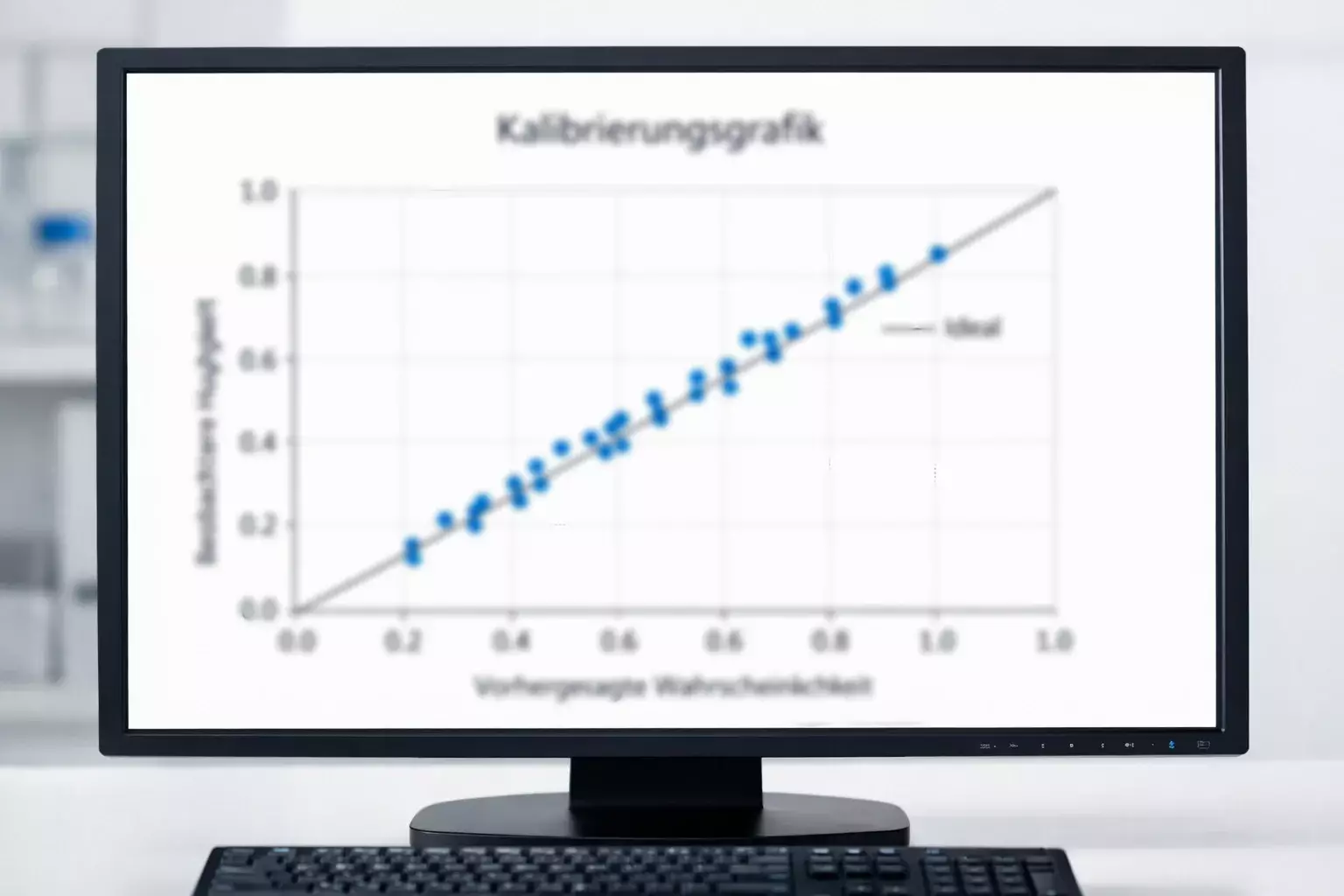
Die Kalibrierung eines Prognosemodells misst, wie gut die ausgegebenen Wahrscheinlichkeiten mit den tatsächlichen Häufigkeiten der Ereignisse übereinstimmen. Ein perfekt kalibriertes Modell würde folgendes zeigen: Von allen Spielen, denen es 70 Prozent Heimsiegwahrscheinlichkeit zugewiesen hat, enden tatsächlich 70 Prozent mit einem Heimsieg. Von allen Spielen mit 30 Prozent Auswärtssiegchance gewinnt der Gast in 30 Prozent der Fälle.
Diese Übereinstimmung ist in der Realität nie perfekt, aber je näher ein Modell ihr kommt, desto verlässlicher sind seine Prognosen. Die Kalibrierung lässt sich grafisch durch sogenannte Reliability-Diagramme darstellen. Auf der horizontalen Achse werden die vorhergesagten Wahrscheinlichkeiten aufgetragen, auf der vertikalen die beobachteten Häufigkeiten. Bei perfekter Kalibrierung liegen alle Punkte auf der Diagonalen.
Typische Abweichungen von der perfekten Kalibrierung zeigen charakteristische Muster. Überkonfidente Modelle überschätzen systematisch die Wahrscheinlichkeit des vorhergesagten Ergebnisses. Sie prognostizieren zum Beispiel 80 Prozent Heimsiegchance, aber nur 65 Prozent dieser Spiele enden tatsächlich mit einem Heimsieg. Unterkonfidente Modelle zeigen das umgekehrte Muster: Ihre Prognosen sind zu konservativ, die tatsächlichen Frequenzen liegen über den vorhergesagten.
Die Ursachen für mangelnde Kalibrierung sind vielfältig. Überkonfidenz entsteht oft durch Überanpassung an historische Daten. Ein Modell lernt Muster, die in der Vergangenheit existierten, aber nicht generalisierbar sind. Unterkonfidenz kann auf eine zu starke Regression zur Mitte hindeuten, bei der das Modell extreme Wahrscheinlichkeiten vermeidet, obwohl sie gerechtfertigt wären.
Die Bewertung der Kalibrierung erfordert eine ausreichende Datenbasis. Bei wenigen Spielen sind Abweichungen von der Diagonalen durch Zufall erklärbar. Erst bei Hunderten von Prognosen werden systematische Muster erkennbar. Die Champions League mit ihrer begrenzten Anzahl von Spielen pro Saison erschwert diese Bewertung. Seriöse Analysen kombinieren daher Champions-League-Daten mit Prognosen aus nationalen Ligen und anderen Wettbewerben.
Neben der Kalibrierung ist die Trennschärfe ein wichtiges Qualitätsmerkmal. Ein Modell kann perfekt kalibriert sein und dennoch wenig nützlich, wenn es allen Spielen ähnliche Wahrscheinlichkeiten zuweist. Ein nützliches Modell differenziert stark zwischen den Spielen und vergibt sowohl hohe als auch niedrige Wahrscheinlichkeiten, die dann auch entsprechend eintreten.
Der Brier-Score kombiniert Kalibrierung und Trennschärfe in einer einzigen Kennzahl. Er misst die mittlere quadratische Abweichung zwischen vorhergesagter Wahrscheinlichkeit und tatsächlichem Ergebnis. Je niedriger der Brier-Score, desto besser das Modell. Ein Brier-Score von null würde perfekte Vorhersagen bedeuten, ein Brier-Score von 0,25 entspricht dem blinden Raten mit jeweils 50 Prozent für alle Ausgänge.
Die besten öffentlich verfügbaren Fußballprognosemodelle erreichen Brier-Scores um 0,19 bis 0,21 für Dreierausgänge. Das klingt nach geringem Abstand zu 0,25, bedeutet aber über viele Spiele einen signifikanten Informationsgewinn gegenüber dem Zufall. Für den einzelnen Nutzer ist es sinnvoll, mehrere Modelle zu vergleichen und jene zu bevorzugen, die über längere Zeiträume gute Kalibrierung und Trennschärfe zeigen.
Wahrscheinlichkeitsbasierte Strategien für Champions League Wetten
Die Anwendung wahrscheinlichkeitsbasierter Ansätze auf die Champions League erfordert spezifische Überlegungen, die über die allgemeine Theorie hinausgehen. Der Wettbewerb hat Eigenheiten, die bei der Strategieentwicklung berücksichtigt werden sollten.
Das neue Ligaphasenformat mit 36 Teams und acht Spielen pro Mannschaft schafft eine andere Dynamik als das alte Gruppenformat. Die Varianz innerhalb der Saison ist höher, weil jedes Team gegen unterschiedliche Gegner antritt und direkte Vergleiche fehlen. Für die Prognose bedeutet das: Tabellenplatzierungen entwickeln sich weniger linear als im alten Format, und Überraschungen sind häufiger.
Die Qualität der verfügbaren Informationen variiert je nach Phase des Wettbewerbs. Zu Saisonbeginn basieren die Prognosen stärker auf strukturellen Faktoren wie Kaderqualität und historischer Stärke. Im Saisonverlauf gewinnen aktuelle Leistungsdaten an Gewicht. Die KI-Modelle passen ihre Gewichtungen entsprechend an, aber der Nutzer sollte sich bewusst sein, dass frühe Saisonprognosen mit größerer Unsicherheit behaftet sind als späte.
Die Markttiefe bei Champions-League-Spielen ist typischerweise hoch. Viele Wettanbieter konkurrieren um Kunden, was zu effizienten Quoten führt. Systematische Value-Gelegenheiten sind seltener als in kleineren Ligen oder Wettbewerben mit geringerer Aufmerksamkeit. Wer glaubt, in der Champions League regelmäßig den Markt zu schlagen, sollte diese Annahme kritisch hinterfragen.
Die zeitliche Strukturierung der Einsätze verdient Beachtung. In der Ligaphase gibt es Spieltage mit vielen parallelen Partien. Die Versuchung, auf viele Spiele gleichzeitig zu setzen, ist groß, birgt aber das Risiko der Überexposition. Das Kelly-Kriterium bezieht sich auf den Einsatz bei einer einzelnen Wette, nicht auf die Summe mehrerer gleichzeitiger Wetten. Bei mehreren Einsätzen am selben Tag sollte das Gesamtrisiko im Blick behalten werden.
Die psychologische Dimension ist nicht zu unterschätzen. Wahrscheinlichkeitsbasiertes Denken erfordert Disziplin. Es wird Tage geben, an denen alle Prognosen falsch liegen, obwohl die Wahrscheinlichkeiten jeweils bei 60 oder 65 Prozent lagen. Solche Serien sind statistisch erwartbar, fühlen sich aber wie Versagen an. Der langfristige Erfolg hängt davon ab, ob man in solchen Phasen die Nerven behält und die Strategie beibehält.
Ein realistisches Erwartungsmanagement gehört ebenfalls zur wahrscheinlichkeitsbasierten Strategie. Selbst ein perfekt kalibriertes Modell mit echtem Value garantiert keine Gewinne auf kurze Sicht. Die Varianz ist hoch, und auch bei positivem Erwartungswert kann das Ergebnis über eine Saison negativ ausfallen. Erst über Hunderte von Wetten gleichen sich die Schwankungen aus. Wer nicht bereit ist, diesen langen Atem mitzubringen, sollte das wahrscheinlichkeitsbasierte Wetten als Analysewerkzeug nutzen, nicht als Gewinnstrategie.
Die Grenzen probabilistischer Prognosen
Bei aller Überlegenheit des wahrscheinlichkeitsbasierten Ansatzes gegenüber festen Tipps bleiben fundamentale Grenzen bestehen. Diese Grenzen sind nicht technischer, sondern prinzipieller Natur. Sie folgen aus der Natur des Fußballs als komplexes System mit vielen interagierenden Faktoren.
Die erste Grenze liegt in der Unvollständigkeit der Daten. Kein Modell kann alle relevanten Faktoren erfassen, weil viele dieser Faktoren nicht messbar sind. Die Stimmung in der Kabine, die Motivation einzelner Spieler, die Qualität der Regeneration nach dem letzten Spiel, all das beeinflusst die Leistung, entzieht sich aber der Quantifizierung. Die ausgewiesenen Wahrscheinlichkeiten sind daher immer Schätzungen unter Unsicherheit über die tatsächlichen Einflussfaktoren.
Die zweite Grenze betrifft die Modellierung von Interaktionen. Fußball ist ein Mannschaftssport, in dem das Zusammenspiel der Einzelteile mehr ergibt als ihre Summe. Ein Team kann auf dem Papier schwächer sein als der Gegner und dennoch überlegen spielen, weil die taktische Abstimmung besser funktioniert. Diese emergenten Eigenschaften sind schwer zu modellieren und führen zu systematischen Prognosefehlern.
Die dritte Grenze ist die Reflexivität des Prognoseobjekts. Im Gegensatz zu physikalischen Systemen reagieren Fußballteams auf Prognosen über sie. Wenn ein Modell einem Team hohe Wahrscheinlichkeiten zuweist und diese Information öffentlich wird, kann das die Erwartungen und damit das Verhalten der Beteiligten beeinflussen. Der Underdog-Effekt, bei dem das vermeintlich schwächere Team durch die Außenseiterrolle motiviert wird, ist ein bekanntes Beispiel für diese Reflexivität.
Die vierte Grenze liegt in seltenen Ereignissen. Wahrscheinlichkeitsmodelle sind für durchschnittliche Fälle optimiert, nicht für Extreme. Ein Spieler, der normalerweise fünf Prozent seiner Fernschüsse verwandelt, kann an einem Tag drei Traumtore schießen. Solche Ausreißer sind in der Wahrscheinlichkeitsverteilung enthalten, aber ihre konkrete Manifestation ist nicht vorhersagbar.
Schließlich gibt es das Problem der Modellauswahl. Es existieren viele verschiedene KI-Ansätze zur Fußballprognose, von einfachen Regressionsmodellen bis zu komplexen neuronalen Netzen. Jeder Ansatz hat seine Stärken und Schwächen, und keiner dominiert die anderen in allen Situationen. Die Wahl des Modells beeinflusst die resultierenden Wahrscheinlichkeiten erheblich, ohne dass es eine objektive Grundlage für die Entscheidung gibt.
Diese Grenzen sollten nicht entmutigen, sondern zu epistemischer Bescheidenheit mahnen. Die probabilistische Prognose ist besser als die kategorische, aber sie bleibt eine Annäherung an eine Wahrheit, die wir nicht vollständig erfassen können. Der Wert liegt nicht in der Illusion von Präzision, sondern in der ehrlichen Kommunikation von Unsicherheit.
Die Zukunft wahrscheinlichkeitsbasierter Fußballprognosen
Die Methoden zur probabilistischen Fußballprognose entwickeln sich kontinuierlich weiter. Neue Datenquellen, verbesserte Algorithmen und wachsende Rechenkapazitäten verschieben die Grenzen des Machbaren. Ergänzend dazu bieten wir spezialisierte xG-Vorhersagen für alle Partien an. Gleichzeitig entstehen neue Herausforderungen, die gelöst werden müssen.
Die Integration von Tracking-Daten ist ein vielversprechender Entwicklungspfad. Moderne Stadien erfassen die Position jedes Spielers mehrfach pro Sekunde. Diese Daten ermöglichen Analysen, die weit über traditionelle Statistiken hinausgehen. Die Bewegungsmuster vor Toren, die Raumkontrolle in verschiedenen Spielphasen, die physische Belastung einzelner Spieler, all das kann in Prognosen einfließen und sie präziser machen.
Die Verarbeitung unstrukturierter Informationen durch KI wird ebenfalls zunehmen. Pressekonferenzen, Social-Media-Posts, Nachrichtenartikel, all diese Quellen enthalten Hinweise auf die aktuelle Verfassung eines Teams, die bisher nur manuell ausgewertet werden konnten. Natural Language Processing ermöglicht die automatische Extraktion relevanter Informationen und ihre Integration in Prognosemodelle.

Die Personalisierung von Prognosen ist ein weiterer Trend. Statt einer allgemeinen Wahrscheinlichkeit könnte das Modell verschiedene Szenarien durchrechnen und dem Nutzer erlauben, eigene Annahmen einzubringen. Wer glaubt, dass ein bestimmter Spieler einen großen Tag haben wird, könnte diese Information einspeisen und sehen, wie sie die Prognose verändert.
Die Verbesserung der Kommunikation von Unsicherheit bleibt eine Herausforderung. Viele Menschen haben Schwierigkeiten, Wahrscheinlichkeiten intuitiv zu verstehen. Visualisierungen, Vergleiche mit bekannten Wahrscheinlichkeiten und interaktive Elemente können helfen, aber eine universelle Lösung ist noch nicht gefunden.
Die ethischen Fragen rund um KI-Prognosen werden an Bedeutung gewinnen. Wenn Algorithmen besser werden, steigt die Gefahr der Marktmanipulation und der Ausnutzung von Informationsasymmetrien. Die Regulierung muss mit der technischen Entwicklung Schritt halten, was bisher nur bedingt gelingt.
Trotz all dieser Entwicklungen wird der fundamentale Charakter probabilistischer Prognosen derselbe bleiben. Sie werden Aussagen über Wahrscheinlichkeiten machen, nicht über Gewissheiten. Sie werden manchmal recht haben und manchmal nicht. Sie werden ein Werkzeug sein für informierte Beobachter, nicht eine Garantie für Erfolg. Wer das verstanden hat, kann von den Fortschritten profitieren, ohne unrealistischen Erwartungen zu erliegen.
Die Champions League wird weiterhin ein Wettbewerb sein, in dem Überraschungen zum Kern des Erlebnisses gehören. Kein KI-Modell wird die Magie eines unerwarteten Triumphs ersetzen können oder wollen. Die probabilistische Prognose ordnet diese Überraschungen lediglich in einen Rahmen ein, der sie erwartbar macht, ohne sie vorherzusagen. Und genau darin liegt ihr Wert für alle, die den Fußball nicht nur erleben, sondern auch verstehen wollen.
Die Demokratisierung von Prognosewerkzeugen ist ein weiterer bemerkenswerter Trend. Was früher nur großen Wettanbietern und spezialisierten Analysten zur Verfügung stand, ist heute für jeden zugänglich. Kostenlose Plattformen bieten Wahrscheinlichkeitsschätzungen an, Open-Source-Modelle können mit wenigen Klicks auf eigene Daten angewandt werden, und die Grundlagen der probabilistischen Analyse lassen sich in Online-Kursen erlernen. Diese Entwicklung hat das Wissen um Wahrscheinlichkeiten verbreitet, aber auch neue Herausforderungen geschaffen.
Die Gefahr besteht darin, dass oberflächliches Verständnis zu falschen Schlussfolgerungen führt. Wer eine Wahrscheinlichkeit von 80 Prozent sieht und daraus ableitet, das Ergebnis sei praktisch sicher, hat den Kern der probabilistischen Denkweise nicht verstanden. Die Bildung im Umgang mit Wahrscheinlichkeiten hinkt der Verfügbarkeit von Prognosewerkzeugen hinterher. Hier liegt eine Aufgabe für Analysten und Kommunikatoren: nicht nur Zahlen zu liefern, sondern auch deren Interpretation zu schulen.
Die kulturelle Dimension verdient ebenfalls Erwähnung. In verschiedenen Fußballkulturen werden Prognosen unterschiedlich aufgenommen. In manchen Traditionen gilt das nüchterne Rechnen mit Wahrscheinlichkeiten als respektlos gegenüber der Emotionalität des Sports. In anderen wird es als überfällige Modernisierung begrüßt. Die Champions League als paneuropäischer Wettbewerb bringt diese unterschiedlichen Perspektiven zusammen und zeigt, dass probabilistisches Denken eine Ergänzung zum emotionalen Erleben sein kann, nicht dessen Ersatz.
Die Frage nach dem Verhältnis von Prognose und Freude am Spiel ist letztlich eine persönliche. Manche Fans wollen jeden Faktor analysieren und jede Wahrscheinlichkeit kennen. Andere bevorzugen die unschuldige Überraschung beim Anschauen des Spiels. Beide Haltungen haben ihre Berechtigung, und die probabilistische Analyse drängt sich niemandem auf. Sie ist ein Werkzeug für diejenigen, die es nutzen möchten, und ignorierbar für alle anderen.
Für diejenigen, die sich auf die Reise der probabilistischen Fußballanalyse einlassen, wartet eine faszinierende Welt. Sie werden lernen, Spiele anders zu sehen und Ergebnisse anders zu bewerten. Sie werden verstehen, warum Überraschungen keine Widerlegung ihrer Analysen sind, sondern deren Bestätigung. Und sie werden die Champions League mit neuen Augen betrachten, ohne dabei die alte Begeisterung zu verlieren.