AI Champions League Vorhersage simuliert – Wie Supercomputer die CL durchspielen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Wenn Sportjournalisten verkünden, dass der Opta Supercomputer dem FC Arsenal eine 22-prozentige Chance auf den Champions-League-Titel gibt, klingt das beeindruckend präzise. Doch was verbirgt sich hinter dieser Zahl? Wie kommt ein Computer zu solchen Aussagen, und warum sollte man ihnen Glauben schenken? Die Antwort führt in die faszinierende Welt der Simulationsmodelle, genauer gesagt zu einer Methode, die ursprünglich für die Berechnung von Atombombenexplosionen entwickelt wurde und heute Fußballergebnisse vorhersagt.
Simulierte Vorhersagen unterscheiden sich fundamental von traditionellen Prognosen. Statt eine einzelne Einschätzung abzugeben, spielen sie den gesamten Wettbewerb tausende Male durch und analysieren die Ergebnisse. Das Resultat ist keine simple Aussage über Sieg oder Niederlage, sondern eine nuancierte Landschaft von Wahrscheinlichkeiten. Diese Herangehensweise hat die Art und Weise revolutioniert, wie wir über die Zukunft der Königsklasse nachdenken.
Was bedeutet simulierte Vorhersage?
Der Begriff Simulation beschreibt im wissenschaftlichen Kontext die Nachbildung eines realen Prozesses mit Hilfe mathematischer Modelle. Im Fußball bedeutet das: Ein Computer spielt ein Spiel oder einen ganzen Wettbewerb virtuell durch, wobei die Ergebnisse nicht festgelegt, sondern vom Modell unter Berücksichtigung von Wahrscheinlichkeiten erzeugt werden.
Das Grundprinzip: Viele Würfe statt einer Vorhersage
Stellen Sie sich vor, Sie wollen herausfinden, mit welcher Wahrscheinlichkeit Bayern München gegen Real Madrid gewinnt. Die traditionelle Methode wäre, alle verfügbaren Daten zu analysieren und eine Einschätzung abzugeben: Bayern hat 55 Prozent Siegchance. Diese Zahl basiert auf komplexen Berechnungen, aber sie ist letztlich eine Punktschätzung.
Die simulationsbasierte Methode geht anders vor. Sie definiert zunächst ein Modell, das beschreibt, wie Tore entstehen. Dann lässt sie dieses Modell das Spiel nicht einmal, sondern zehntausend Mal durchlaufen. In jedem Durchlauf fallen die Tore leicht unterschiedlich, weil Zufallselemente eingebaut sind. Am Ende zählt der Computer: In wie vielen der zehntausend Simulationen hat Bayern gewonnen? Waren es 5.500, entspricht das einer Siegwahrscheinlichkeit von 55 Prozent.
Der Vorteil dieses Ansatzes liegt in der Transparenz. Man sieht nicht nur das Endergebnis, sondern auch die Verteilung aller möglichen Ergebnisse. Vielleicht gewinnt Bayern in 55 Prozent der Fälle, aber in 70 Prozent dieser Siege nur knapp. Solche Nuancen gehen bei traditionellen Vorhersagen verloren.

Die Monte-Carlo-Methode
Die mathematische Grundlage dieser Simulationen trägt den poetischen Namen Monte-Carlo-Methode, benannt nach dem berühmten Spielcasino im Fürstentum Monaco. Der Name ist kein Zufall, denn das Prinzip basiert auf kontrolliertem Zufall, ähnlich wie beim Roulette.
Die Monte-Carlo-Methode wurde in den 1940er Jahren von Wissenschaftlern entwickelt, die am Manhattan-Projekt arbeiteten. Sie brauchten eine Möglichkeit, komplexe physikalische Prozesse zu berechnen, bei denen zu viele Variablen im Spiel waren, um exakte Lösungen zu finden. Die Idee war genial: Statt zu berechnen, was genau passieren wird, simuliert man den Prozess viele Male mit zufälligen Ausgangsbedingungen und analysiert die Häufigkeitsverteilung der Ergebnisse.
Heute wird die Monte-Carlo-Methode in unzähligen Bereichen eingesetzt: von der Finanzwirtschaft über die Medizin bis hin zur Wettervorhersage. Im Fußball ermöglicht sie es, die Ungewissheit explizit zu modellieren, anstatt sie zu ignorieren.
Deterministische versus probabilistische Vorhersagen
Ein wesentlicher Unterschied zwischen Simulationsmodellen und anderen Prognosemethoden liegt in der Behandlung von Unsicherheit. Deterministische Vorhersagen geben ein konkretes Ergebnis aus: Bayern gewinnt 2:1. Probabilistische Vorhersagen liefern Wahrscheinlichkeitsverteilungen: Mit 12 Prozent Wahrscheinlichkeit gewinnt Bayern 2:1, mit 9 Prozent 1:0, mit 8 Prozent 3:1, und so weiter.
Simulationsmodelle sind von Natur aus probabilistisch. Sie akzeptieren, dass die Zukunft nicht vorhersagbar ist, und versuchen stattdessen, die Bandbreite möglicher Zukünfte zu quantifizieren. Das ist ehrlicher und im Fußball auch realistischer, denn jeder Fan weiß, dass selbst haushohe Favoriten manchmal verlieren.
So funktioniert eine Champions League Simulation
Die technische Umsetzung einer Champions-League-Simulation ist komplexer, als man zunächst vermuten könnte. Es geht nicht nur darum, einzelne Spiele zu simulieren, sondern einen ganzen Wettbewerb mit Ligaphase, Playoffs und K.o.-Runden.
Der Ablauf einer einzelnen Simulation
Jeder Durchlauf beginnt mit dem aktuellen Stand des Wettbewerbs. Für noch nicht gespielte Partien zieht das Modell ein Ergebnis, das auf den Stärkerelationen der Teams basiert. Die Anzahl der Tore wird typischerweise aus einer Poisson-Verteilung gezogen, deren Parameter von der erwarteten Torquote abhängen.
Nehmen wir an, das Modell erwartet für ein Spiel zwischen Liverpool und Inter Mailand durchschnittlich 1,8 Tore für Liverpool und 1,2 für Inter. Für diese eine Simulation würfelt es ein konkretes Ergebnis aus, das diesen Erwartungswerten entspricht. Vielleicht wird es 2:1 für Liverpool, vielleicht 0:0, vielleicht 3:2 für Inter. Jedes dieser Ergebnisse hat eine bestimmte Wahrscheinlichkeit, und das Modell wählt eines gemäß dieser Wahrscheinlichkeiten aus.
Nach jedem Spiel aktualisiert die Simulation den Tabellenstand, prüft, wer weiterkommt, und führt die nächste Runde durch. Am Ende steht ein Sieger. Dann beginnt der Prozess von vorn mit dem zweiten Durchlauf.

Zehntausend Durchläufe und ihre Bedeutung
Die Anzahl der Durchläufe ist kein willkürlich gewählter Wert. Sie folgt statistischen Überlegungen zur Genauigkeit der Ergebnisse. Bei zehntausend Simulationen kann man davon ausgehen, dass die relativen Häufigkeiten stabil sind und nicht mehr stark schwanken würden, wenn man weitere Durchläufe hinzufügt.
Mathematisch ausgedrückt: Der Standardfehler der geschätzten Wahrscheinlichkeit sinkt mit der Quadratwurzel der Anzahl der Durchläufe. Bei zehntausend Simulationen liegt der Standardfehler für eine 50-Prozent-Wahrscheinlichkeit bei etwa 0,5 Prozentpunkten. Das ist genau genug für die meisten praktischen Anwendungen.
Manche Anbieter führen noch mehr Durchläufe durch. Hunderttausend sind keine Seltenheit, besonders wenn man sehr kleine Wahrscheinlichkeiten genau schätzen will. Die Frage, wie wahrscheinlich es ist, dass ein Außenseiter den Titel holt, erfordert mehr Durchläufe als die Frage nach dem Favoriten.
Die Zufallskomponente verstehen
Ein häufiges Missverständnis betrifft die Rolle des Zufalls in diesen Simulationen. Manche Kritiker argumentieren, dass Computer keine echte Zufälligkeit erzeugen können und die Simulationen daher fehlerhaft seien. Doch dieser Einwand geht am Kern der Methode vorbei.
Die Zufallszahlen in Simulationen sind tatsächlich pseudozufällig, das heißt, sie werden durch Algorithmen erzeugt, die deterministische Regeln befolgen. Aber für statistische Zwecke ist das völlig ausreichend. Die Qualität moderner Pseudozufallsgeneratoren ist so hoch, dass sie für praktische Anwendungen nicht von echtem Zufall zu unterscheiden sind.
Wichtiger ist, dass der simulierte Zufall die reale Ungewissheit im Fußball widerspiegelt. Niemand behauptet, dass das Modell weiß, wie ein Spiel ausgeht. Der Zufall repräsentiert das, was wir nicht wissen: Tagesform, Schiedsrichterentscheidungen, individuelle Brillanz und tausend andere Faktoren, die ein Spiel beeinflussen.
Der Opta Supercomputer im Detail
Der Begriff Supercomputer klingt nach beeindruckender Hardware, nach blinkenden Lichtern in klimatisierten Rechenzentren. In der Realität ist der Opta Supercomputer weniger ein Gerät als vielmehr eine Software, ein mathematisches Modell, das die Methodik von Opta Sports umsetzt.
Datenquellen und ihre Verarbeitung
Opta, eine Tochtergesellschaft von Stats Perform, sammelt detaillierte Daten von Fußballspielen weltweit. Jeder Pass, jeder Schuss, jedes Foul wird erfasst und kategorisiert. Diese Datenfülle bildet die Grundlage für die Simulationsmodelle.
Für Champions-League-Prognosen fließen historische Leistungsdaten der Teams ein, ergänzt um aktuelle Formkurven und die Qualität der Kader. Das Modell berücksichtigt, wie Teams gegen unterschiedlich starke Gegner abschneiden, und passt die erwarteten Torquoten entsprechend an.
Besonders wichtig sind die Expected-Goals-Daten, die messen, wie viele Tore eine Mannschaft aufgrund ihrer Torchancen hätte erzielen müssen. Ein Team mit einem hohen xG-Wert, das aber nur unterdurchschnittlich viele Tore erzielt hat, wird vom Modell höher eingeschätzt, als die nackten Zahlen vermuten ließen.
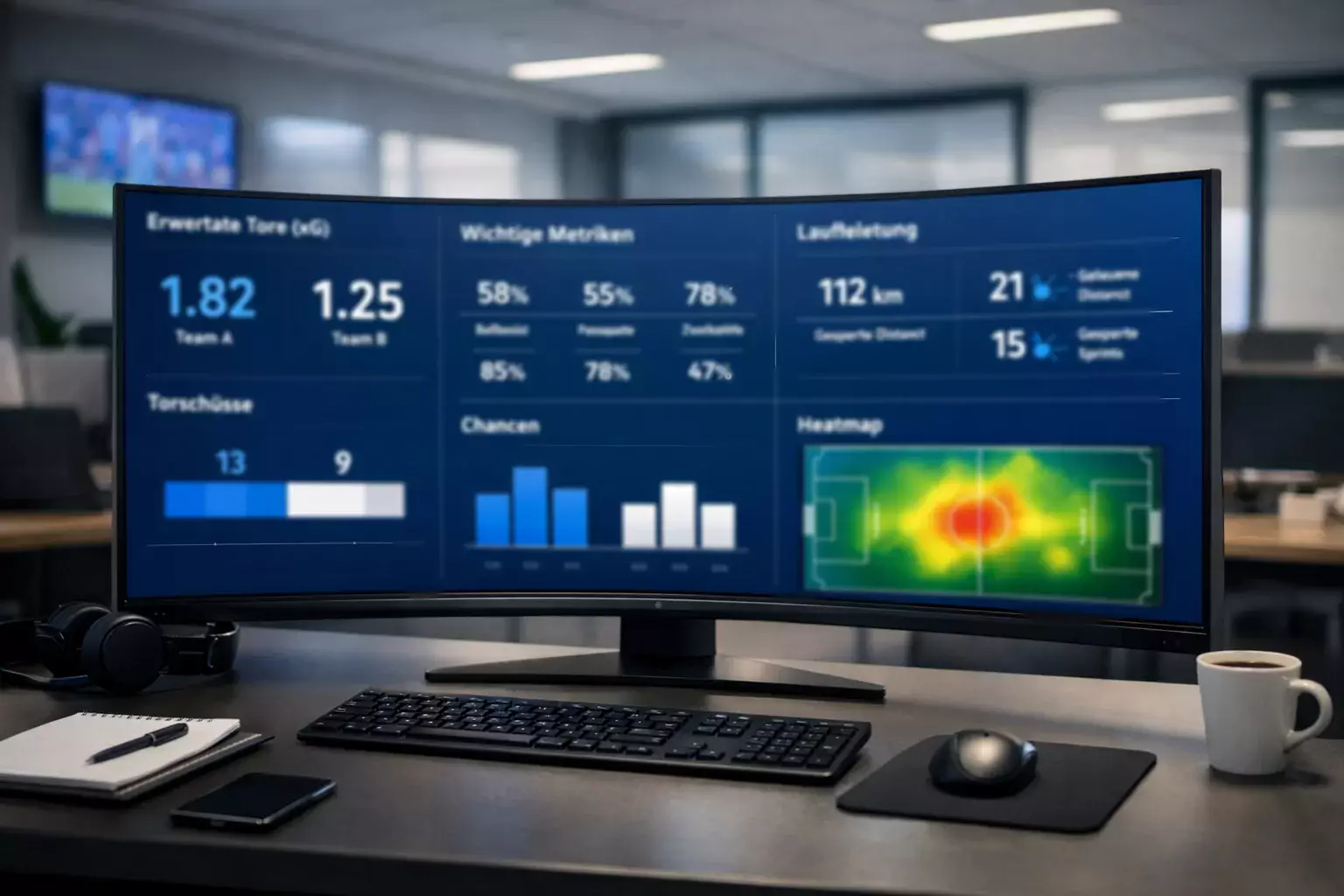
Die Methodik hinter den Prognosen
Das genaue Innenleben des Opta-Modells ist ein Geschäftsgeheimnis, doch die Grundprinzipien sind bekannt. Das Modell kombiniert Elo-ähnliche Ratings, die die Gesamtstärke eines Teams messen, mit spezifischen Faktoren wie Offensiv- und Defensivqualität, Heimvorteil und aktuelle Form.
Für jedes Spiel berechnet das Modell zunächst die erwarteten Torquoten beider Teams. Diese Werte fließen dann in die Monte-Carlo-Simulation ein, die das Spiel virtuell durchführt. Die Ergebnisse werden aggregiert, um Wahrscheinlichkeiten für Sieg, Unentschieden und Niederlage zu ermitteln.
Für Turnierprognosen wie die Frage, wer die Champions League gewinnt, wird der gesamte verbleibende Wettbewerb simuliert. Das Modell berücksichtigt dabei auch die Auslosungswahrscheinlichkeiten für zukünftige Runden und die verschiedenen möglichen Pfade zum Finale.
Die Rolle von Expected Goals in Simulationen
Ein wesentlicher Bestandteil moderner Simulationsmodelle ist die Integration von Expected Goals. Diese Metrik geht über bloße Torstatistiken hinaus und bewertet die Qualität der Chancen, die ein Team kreiert und zulässt.
In der Simulation bedeutet das: Ein Team mit einem xG-Wert von 2,0 pro Spiel, das aber nur 1,5 Tore pro Spiel erzielt hat, wird nicht nach seiner tatsächlichen Torausbeute bewertet. Das Modell erkennt, dass die Unterperformance wahrscheinlich zufälliger Natur ist und korrigiert die erwarteten Torquoten nach oben.
Diese Korrektur ist statistisch fundiert. Studien haben gezeigt, dass xG ein besserer Prädiktor für zukünftige Torausbeute ist als die tatsächlich erzielten Tore. Ein Team, das seine Chancen systematisch verwandelt, wird langfristig eher zur Mitte regredieren als dauerhaft überperformen.
Historische Trefferquoten und ihre Interpretation
Opta veröffentlicht regelmäßig Daten über die Genauigkeit seiner Vorhersagen. Dabei zeigt sich ein Muster, das für alle seriösen Prognosemodelle gilt: Die Vorhersagen sind besser als Zufall, aber weit entfernt von Perfektion.
Konkret bedeutet das: Wenn das Modell einem Team 60 Prozent Siegchance gibt, gewinnt dieses Team historisch gesehen tatsächlich in etwa 60 Prozent der Fälle. Das klingt trivial, ist aber ein wichtiges Qualitätsmerkmal. Ein schlecht kalibriertes Modell würde bei 60-Prozent-Vorhersagen vielleicht nur in 40 Prozent der Fälle richtig liegen.
Die Trefferquote bei einzelnen Spielen liegt typischerweise bei etwa 50 bis 55 Prozent, wenn man nur Sieg, Unentschieden oder Niederlage betrachtet. Das klingt nicht besonders beeindruckend, ist aber im Kontext des Fußballs ein solides Ergebnis. Der Sport ist inhärent unvorhersehbar, und kein Modell kann diese Unvorhersehbarkeit eliminieren.
Transparenz der Kommunikation
Ein Verdienst von Opta ist die relativ offene Kommunikation über die Limitationen der eigenen Prognosen. Die veröffentlichten Wahrscheinlichkeiten werden als das präsentiert, was sie sind: Schätzungen auf Basis verfügbarer Daten, keine Garantien.
Diese Transparenz unterscheidet seriöse Anbieter von unseriösen. Wer behauptet, sichere Tipps zu haben, versteht entweder sein eigenes Modell nicht oder führt sein Publikum bewusst in die Irre. Die Ehrlichkeit über Unsicherheiten ist ein Qualitätsmerkmal, kein Schwäche.
Simulierte Tabellenprognosen für die CL-Ligaphase
Das neue Format der Champions League mit einer Ligaphase statt traditioneller Gruppen ist wie geschaffen für Simulationsmodelle. Anstatt vier Teams in einer Gruppe zu analysieren, müssen nun 36 Teams in einem komplexen Ligasystem berücksichtigt werden.
Wie Tabellenprognosen entstehen
Jede Simulation der Ligaphase führt alle 144 Spiele durch und ermittelt die resultierende Tabelle. Nach zehntausend Durchläufen weiß das Modell, wie oft jedes Team auf welchem Platz gelandet ist.
Die Ergebnisse werden typischerweise in Wahrscheinlichkeiten ausgedrückt: Team X landet mit 35 Prozent Wahrscheinlichkeit unter den ersten Acht und qualifiziert sich direkt für das Achtelfinale. Mit 45 Prozent Wahrscheinlichkeit landet es auf den Plätzen 9 bis 24 und muss in die Playoffs. Mit 20 Prozent scheidet es aus.
Diese Prognosen aktualisieren sich mit jedem gespielten Spieltag. Sobald neue Ergebnisse vorliegen, werden die Simulationen neu gerechnet, und die Wahrscheinlichkeiten verschieben sich. Ein unerwarteter Sieg kann die Aussichten eines Teams dramatisch verbessern, eine Niederlage sie einbrechen lassen.
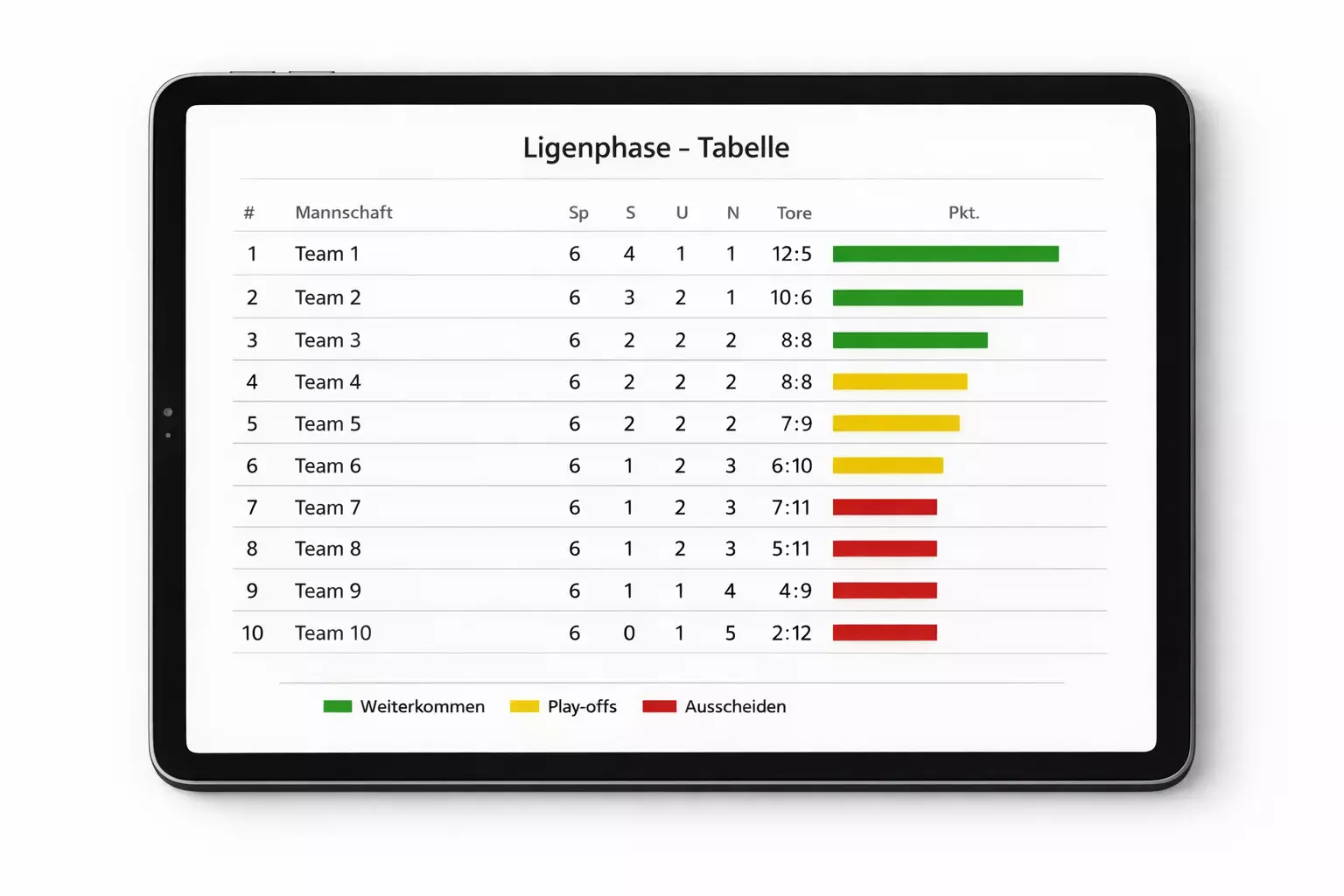
Warum simulierte Tabellenprognosen oft erstaunlich akkurat sind
Trotz aller Unwägbarkeiten im Einzelspiel sind die aggregierten Tabellenprognosen oft überraschend treffsicher. Das liegt an einem statistischen Phänomen namens Gesetz der großen Zahlen.
Einzelne Spiele sind schwer vorhersagbar, weil zu viel vom Zufall abhängt. Aber über viele Spiele hinweg mitteln sich die Zufallseffekte aus. Die wahre Stärke eines Teams zeigt sich nicht im einzelnen Match, sondern in der Summe vieler Partien.
Die Ligaphase mit ihren acht Spielen pro Team liefert mehr Datenpunkte als das alte Gruppenformat mit sechs Spielen. Das macht die Tabelle aussagekräftiger und die Prognosen zuverlässiger. Gleichzeitig sorgt die größere Teilnehmerzahl dafür, dass einzelne Ausreißer weniger Einfluss auf die Gesamtstruktur haben.
Die Dynamik während der Saison
Besonders spannend wird es, wenn die Ligaphase fortschreitet und sich das Tableau konkretisiert. Die Simulation zeigt dann nicht nur den wahrscheinlichsten Ausgang, sondern auch die kritischen Spiele, in denen über Weiterkommen oder Ausscheiden entschieden wird.
Ein Team auf Platz 10 mit noch zwei ausstehenden Spielen gegen schwache Gegner hat andere Perspektiven als ein Team auf demselben Platz mit zwei Spielen gegen die Topteams. Die Simulation berücksichtigt diese Unterschiede und quantifiziert die jeweiligen Chancen.
Für Fans ergibt sich daraus eine neue Art, den Wettbewerb zu verfolgen. Statt nur auf den aktuellen Tabellenstand zu schauen, kann man die Entwicklung der Wahrscheinlichkeiten verfolgen und sehen, wie jedes Ergebnis die Aussichten verändert.
Limitationen von Simulationsmodellen
So beeindruckend die Methodik auch sein mag, Simulationsmodelle haben klare Grenzen, die jeder Nutzer kennen sollte.
Was Simulationen nicht erfassen können
Kein Modell der Welt kann individuelle Brillanz vorhersagen. Wenn Lionel Messi in einem entscheidenden Moment einen genialen Pass spielt oder ein Torhüter eine Serie von Paraden zeigt, die statistisch unwahrscheinlich sind, liegt das außerhalb der Modellkapazitäten.
Ähnliches gilt für taktische Anpassungen während eines Spiels. Wenn ein Trainer zur Halbzeit eine geniale Umstellung vornimmt, die das Spiel dreht, hat das Modell diese Möglichkeit nicht auf dem Schirm. Es basiert auf historischen Durchschnitten, nicht auf der Kreativität einzelner Akteure.
Auch externe Faktoren wie Wetter, Platzverhältnisse oder außergewöhnliche Ereignisse bleiben außen vor. Ein Stromausfall, ein medizinischer Notfall auf der Tribüne oder extreme Witterungsbedingungen können ein Spiel völlig verändern. Solche Black-Swan-Ereignisse sind per Definition nicht vorhersehbar.
Die Tagesformproblematik
Fußballteams sind keine konstanten Größen. Ein Team, das letzte Woche brillierte, kann heute uninspiriert auftreten. Die Gründe dafür sind vielfältig: Motivationsschwankungen, Ermüdung, Ablenkungen durch Transfers oder Vertragsverhandlungen, interne Konflikte.
Simulationsmodelle versuchen, Tagesform durch Gewichtung jüngerer Ergebnisse einzufangen. Aber die tatsächliche Form am Spieltag bleibt unbekannt. Ein Team mit glänzender Form in den letzten Wochen kann ausgerechnet im entscheidenden Spiel einen rabenschwarzen Tag erwischen.
Diese Ungewissheit ist nicht eliminierbar, sondern Teil des Sports. Simulationen machen sie explizit, indem sie eine Bandbreite möglicher Ausgänge zeigen. Aber sie können nicht vorhersagen, welches dieser möglichen Ergebnisse tatsächlich eintritt.
Unvorhersehbare Ereignisse und ihr Einfluss
Die Fußballgeschichte ist voller Momente, die kein Modell hätte vorhersagen können. Das sogenannte Wunder von Istanbul 2005, als Liverpool einen 0:3-Rückstand gegen den AC Mailand aufholte und im Elfmeterschießen gewann, ist ein Paradebeispiel.
Vor dem Finale hätte jede Simulation Mailand als klaren Favoriten gezeigt. Nach der Halbzeit, mit drei Toren Vorsprung für die Italiener, wäre die Wahrscheinlichkeit eines Liverpool-Sieges auf einstellige Prozentbereiche gefallen. Was dann passierte, lag außerhalb jeder statistischen Erwartung.
Solche Ereignisse sind selten, aber sie passieren. Sie erinnern daran, dass Fußball mehr ist als die Summe seiner Statistiken. Die Simulation kann uns sagen, was wahrscheinlich ist, aber nicht, was sein wird.
Was simulierte Vorhersagen leisten können
Trotz aller Limitationen bieten Simulationsmodelle einen echten Mehrwert für alle, die sich intensiver mit der Champions League beschäftigen wollen.
Strukturierte Einschätzung von Chancen
Statt auf Bauchgefühl und vage Eindrücke zu vertrauen, liefern Simulationen quantifizierte Einschätzungen. Man erfährt nicht nur, dass ein Team Favorit ist, sondern auch, wie groß der Abstand zum Verfolger ist. Eine 35-prozentige Titelchance ist etwas anderes als eine 60-prozentige, auch wenn beides als Favoritenstatus bezeichnet werden könnte.
Diese Präzision hilft bei der Einordnung. Wenn der Opta Supercomputer Arsenal und Bayern mit ähnlichen Titelchancen sieht, signalisiert das, dass das Rennen offen ist. Wenn dagegen ein Team mit über 30 Prozent führt und der nächste Verfolger bei 15 Prozent liegt, ist die Hierarchie klarer.
Identifikation von Überraschungskandidaten
Simulationen können Teams identifizieren, deren Chancen vom breiten Publikum unterschätzt werden. Ein Außenseiter mit einer vierprozentigen Titelchance klingt nach wenig, aber vier Prozent bedeuten, dass dieses Team in etwa einem von 25 Turnierdurchläufen gewinnt.
Für Beobachter, die über den Tellerrand der üblichen Verdächtigen hinausschauen wollen, sind solche Informationen wertvoll. Sie zeigen, wo Überraschungen möglich sind und welche Wege zum Erfolg führen könnten.
Verständnis für Wahrscheinlichkeiten entwickeln
Der vielleicht größte Nutzen von Simulationsprognosen liegt in der Bildungswirkung. Wer sich regelmäßig mit probabilistischen Vorhersagen beschäftigt, entwickelt ein besseres Gefühl für Wahrscheinlichkeiten und Unsicherheiten.
Diese Kompetenz überträgt sich auf andere Lebensbereiche. Wer verstanden hat, warum eine 70-prozentige Prognose nicht falsch ist, wenn das Gegenteil eintritt, denkt auch über Wettervorhersagen, Wahlumfragen und medizinische Diagnosen differenzierter nach.
Am Ende sind simulierte Vorhersagen weder Kristallkugel noch nutzlose Spielerei. Sie sind Werkzeuge, die bei richtiger Anwendung wertvolle Einblicke liefern. Wer ihre Stärken und Schwächen kennt, kann sie gewinnbringend nutzen, ohne in die Falle zu tappen, ihnen blind zu vertrauen. Die Champions League bleibt ein Drama mit ungewissem Ausgang, und genau das macht sie so faszinierend.
Praktische Anwendung von Simulationsergebnissen
Wer Simulationsprognosen sinnvoll nutzen will, sollte einige Grundregeln beachten, die den Unterschied zwischen informierter Analyse und blindem Zahlenvertrauen ausmachen.
Wahrscheinlichkeiten richtig lesen
Eine 20-prozentige Titelchance bedeutet, dass das Team in einem von fünf simulierten Turnierverläufen gewinnt. Das klingt nach wenig, ist aber durchaus beachtlich. In einer Liga mit fünf oder sechs realistischen Titelanwärtern ist eine 20-Prozent-Chance ein starkes Signal.
Umgekehrt bedeutet eine 80-prozentige Wahrscheinlichkeit für das Erreichen des Achtelfinals, dass das Team in zwei von zehn Durchläufen ausscheidet. Diese Kehrseite der Medaille wird oft vergessen. Keine Prognose, egal wie hoch die Wahrscheinlichkeit, ist eine Garantie.
Die Kunst liegt darin, Wahrscheinlichkeiten als das zu akzeptieren, was sie sind: Schätzungen unter Unsicherheit. Sie helfen bei der Einordnung, ersetzen aber nicht das Ansehen der Spiele und das eigene Urteil.
Zeitpunkt und Kontext beachten
Simulationsprognosen sind Momentaufnahmen. Sie basieren auf dem Wissensstand zu einem bestimmten Zeitpunkt. Sobald neue Informationen vorliegen, ändern sich die Wahrscheinlichkeiten. Ein Verletzungsbericht am Tag vor dem Spiel kann die Einschätzung dramatisch verschieben.
Kluge Nutzer von Simulationsdaten achten daher immer auf das Datum der Prognose und die berücksichtigten Faktoren. Eine Vorhersage, die vor einer wichtigen Verletzung erstellt wurde, hat andere Implikationen als eine, die diese Information bereits enthält.
Mehrere Quellen vergleichen
Verschiedene Simulationsmodelle nutzen unterschiedliche Methoden und Datenquellen. Wo sich mehrere unabhängige Modelle einig sind, kann man mehr Vertrauen haben. Wo sie stark abweichen, lohnt sich ein genauerer Blick auf die Gründe.
Dieser Vergleich schützt vor Übervertrauen in ein einzelnes Modell. Jedes System hat Stärken und Schwächen, und die Konsensbildung über mehrere Quellen hinweg führt oft zu robusteren Einschätzungen.
Die Zukunft der Simulationsmodelle
Die Entwicklung von Fußballsimulationen schreitet rasant voran. Neue Datenquellen, verbesserte Algorithmen und steigende Rechenleistung ermöglichen immer differenziertere Modelle.

Integration von Trackingdaten
Moderne Stadien sind mit Kameras und Sensoren ausgestattet, die jede Spielerbewegung erfassen. Diese Tracking-Daten ermöglichen Analysen, die weit über traditionelle Statistiken hinausgehen. Wie viel Raum öffnet sich bei bestimmten Laufwegen? Wie schnell reagiert eine Verteidigung auf Positionswechsel?
Die Integration dieser Daten in Simulationsmodelle steht noch am Anfang, verspricht aber erhebliche Verbesserungen. Statt nur zu wissen, dass ein Team viel läuft, kann das Modell lernen, welche Laufwege taktisch sinnvoll sind und welche nicht.
Maschinelles Lernen und adaptive Modelle
Klassische statistische Modelle basieren auf vordefinierten Annahmen. Maschinelles Lernen ermöglicht es, Muster in den Daten zu entdecken, die Menschen übersehen würden. Diese Algorithmen können aus der Vergangenheit lernen, ohne dass jemand ihnen explizit sagen muss, worauf sie achten sollen.
Die Herausforderung liegt darin, Overfitting zu vermeiden und die Ergebnisse interpretierbar zu halten. Ein Modell, das perfekte Vorhersagen macht, aber niemand versteht warum, ist für praktische Anwendungen wenig nützlich.
Grenzen bleiben bestehen
Trotz aller technischen Fortschritte werden Simulationsmodelle niemals perfekt sein. Fußball enthält Elemente, die sich jeder Quantifizierung entziehen: Teamchemie, Motivationsdynamik, die Magie eines besonderen Abends.
Diese Grenzen sind kein Versagen der Wissenschaft, sondern Teil dessen, was Fußball ausmacht. Die besten Modelle werden diejenigen sein, die ihre eigene Unsicherheit ehrlich kommunizieren und den Nutzern helfen, informierte Entscheidungen zu treffen, ohne die Illusion perfekter Vorhersehbarkeit zu erzeugen.
Die Simulation der Champions League ist ein faszinierendes Feld, das Mathematik, Informatik und Sportleidenschaft verbindet. Wer sich darauf einlässt, gewinnt nicht die Fähigkeit, die Zukunft vorherzusagen. Aber er gewinnt ein tieferes Verständnis für die Strukturen und Wahrscheinlichkeiten, die den schönsten Wettbewerb der Fußballwelt prägen.