AI Champions League Vorhersage statistisch – Die Mathematik hinter den Prognosen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Die Champions League fasziniert Millionen von Fans weltweit, und spätestens seit dem Aufkommen von KI-gestützten Vorhersagesystemen stellt sich die Frage: Lässt sich der Ausgang eines Fußballspiels tatsächlich berechnen? Die Antwort ist komplizierter als ein simples Ja oder Nein. Statistische Methoden bilden das Fundament jeder seriösen KI-Prognose, doch wer diese Werkzeuge richtig nutzen will, muss ihre Stärken und Grenzen verstehen. Dieser Artikel taucht ein in die mathematischen Grundlagen, die hinter den Vorhersagen für die Königsklasse stecken, und zeigt, warum ein gesundes Maß an Skepsis gegenüber Zahlen manchmal der beste Ratgeber ist.
Wer sich mit statistischen Fußballvorhersagen beschäftigt, trifft unweigerlich auf Begriffe wie Wahrscheinlichkeitsverteilung, Regression oder Stichprobengröße. Diese Konzepte klingen zunächst trocken und akademisch, doch sie entscheiden darüber, ob eine Prognose fundiert ist oder auf wackeligen Füßen steht. Die gute Nachricht: Man muss kein Mathematikprofessor sein, um die wesentlichen Prinzipien zu verstehen. Die schlechte Nachricht: Viele Plattformen nutzen statistische Begriffe als Marketinginstrument, ohne deren Implikationen ehrlich zu kommunizieren.
Statistische Grundlagen für Fußballvorhersagen
Bevor wir uns den konkreten Anwendungen widmen, lohnt sich ein Blick auf drei fundamentale Konzepte, die jede statistische Fußballanalyse prägen.
Wahrscheinlichkeitsrechnung als Basis
Jede Vorhersage ist im Kern eine Aussage über Wahrscheinlichkeiten. Wenn ein KI-System prognostiziert, dass der FC Bayern München mit 65 Prozent Wahrscheinlichkeit gewinnt, bedeutet das eben nicht, dass Bayern gewinnen wird. Es bedeutet, dass bei hundertmaliger Wiederholung dieses Spiels unter identischen Bedingungen Bayern statistisch gesehen etwa 65 Mal als Sieger vom Platz gehen würde. Diese Unterscheidung klingt banal, wird aber erstaunlich oft missverstanden.
Die Wahrscheinlichkeitsrechnung erlaubt es, verschiedene Szenarien durchzuspielen und deren relative Häufigkeit abzuschätzen. Im Fußball kommt erschwerend hinzu, dass jedes Spiel einzigartig ist. Anders als beim Würfeln oder Münzwerfen gibt es keine perfekt kontrollierten Bedingungen. Spieler haben gute und schlechte Tage, Verletzungen passieren unvorhersehbar, und selbst das Wetter kann den Spielverlauf beeinflussen.
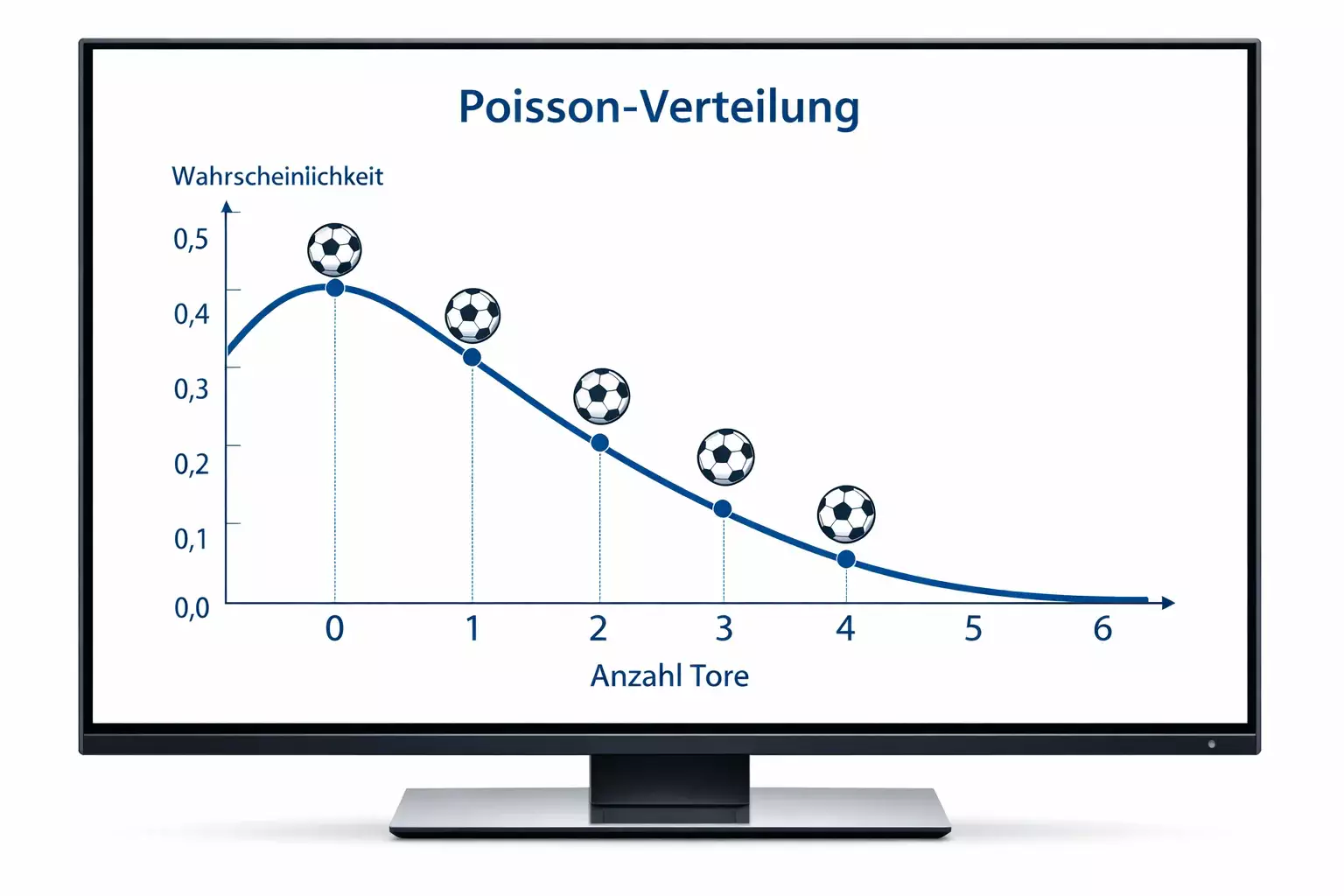
Die Poisson-Verteilung und Fußballtore
Ein Physiker namens Siméon Denis Poisson hätte sich wohl nie träumen lassen, dass seine im 19. Jahrhundert entwickelte Wahrscheinlichkeitsverteilung einmal dazu verwendet werden würde, Fußballergebnisse vorherzusagen. Doch genau das passiert heute in nahezu jedem ernstzunehmenden Prognosemodell.
Die Poisson-Verteilung beschreibt die Wahrscheinlichkeit, wie oft ein seltenes Ereignis in einem festen Zeitintervall auftritt. Tore im Fußball erfüllen diese Kriterien erstaunlich gut: Sie sind relativ selten, treten mehr oder weniger zufällig verteilt über die Spielzeit auf, und ihre durchschnittliche Häufigkeit lässt sich aus historischen Daten ableiten. Studien haben gezeigt, dass die Anzahl der Tore in Fußballspielen tatsächlich annähernd einer Poisson-Verteilung folgt. In der Bundesliga fallen durchschnittlich etwa 2,6 bis 3,0 Tore pro Spiel, und diese mittlere Torquote bildet die Grundlage für die Berechnung einzelner Ergebniswahrscheinlichkeiten.
Das Prinzip funktioniert folgendermaßen: Kennt man die durchschnittliche Torerwartung beider Mannschaften, lässt sich für jedes mögliche Ergebnis die Wahrscheinlichkeit berechnen. Ein 2:1 hat eine andere Wahrscheinlichkeit als ein 0:0 oder ein 4:3. Die Summe aller Ergebnisse, bei denen die Heimmannschaft mehr Tore erzielt, ergibt dann die Siegwahrscheinlichkeit des Heimteams.
Regression zur Mitte
Dieses statistische Phänomen wird im Fußballkontext oft unterschätzt, ist aber für realistische Prognosen unverzichtbar. Regression zur Mitte beschreibt die Tendenz extremer Messwerte, bei nachfolgenden Messungen wieder näher am Durchschnitt zu liegen.
Ein praktisches Beispiel: Eine Mannschaft gewinnt fünf Spiele hintereinander mit jeweils mindestens drei Toren Vorsprung. Die Intuition vieler Fans und leider auch mancher Analysten ist, diese Serie einfach fortzuschreiben. Die Regression zur Mitte lehrt uns jedoch, dass solche Extremwerte mit hoher Wahrscheinlichkeit nicht dauerhaft anhalten werden. Die wahre Leistungsfähigkeit der Mannschaft liegt vermutlich irgendwo zwischen dem normalen Niveau und der Glanzphase.
Dieser Effekt erklärt auch den sogenannten Fluch der Sports Illustrated: Sportler, die auf dem Titelblatt erscheinen, zeigen danach häufig schlechtere Leistungen. Nicht weil das Cover verflucht wäre, sondern weil die herausragende Leistung, die zur Titelgeschichte führte, statistisch gesehen eher ein Ausreißer nach oben war.
Welche Statistiken nutzt KI für Champions League Prognosen?
Moderne KI-Systeme verarbeiten eine beeindruckende Menge an Datenquellen. Die Kunst liegt darin, die wirklich aussagekräftigen Metriken von bloßem statistischem Rauschen zu unterscheiden.
Torbasierte Metriken
Die offensichtlichste Statistik ist gleichzeitig eine der wichtigsten: Wie viele Tore erzielt eine Mannschaft im Durchschnitt, und wie viele kassiert sie? Diese Grundwerte werden jedoch durch den Kontext verfeinert. Heimtore zählen anders als Auswärtstore, denn der Heimvorteil ist statistisch nachweisbar und beträgt je nach Liga zwischen 0,3 und 0,5 Toren pro Spiel.
Darüber hinaus unterscheiden KI-Systeme zwischen der Angriffsstärke und der Defensivstärke einer Mannschaft. Eine Mannschaft, die viele Tore schießt, aber auch viele kassiert, hat ein anderes Profil als eine defensiv starke Truppe mit wenig Torgefahr. Beide können auf dem Papier ähnliche Punkteausbeuten haben, doch ihre Spielweise und damit ihre Prognoseprofile unterscheiden sich erheblich.

Formkurven und Gewichtung
Nicht alle Spiele sind gleich relevant für eine Prognose. Ein Ergebnis aus dem letzten Monat sollte stärker gewichtet werden als eines von vor einem Jahr. KI-Systeme verwenden typischerweise eine abnehmende Gewichtung, bei der jüngere Spiele mehr Einfluss auf die Prognose haben als ältere.
Die Herausforderung besteht darin, die richtige Balance zu finden. Zu starke Gewichtung der jüngsten Ergebnisse macht das Modell anfällig für kurzfristige Schwankungen und Zufallseffekte. Zu geringe Gewichtung ignoriert möglicherweise relevante Veränderungen wie Trainerwechsel, Neuzugänge oder Verletzungen von Schlüsselspielern.
In der Champions League kommt erschwerend hinzu, dass die Spielhäufigkeit geringer ist als in nationalen Ligen. Acht Spiele in der Ligaphase liefern weniger Datenpunkte als 34 Bundesligaspiele. Diese geringere Stichprobengröße macht Prognosen für Europapokalspiele grundsätzlich unsicherer als für Ligapartien.
Heim-Auswärts-Differenzen
Der Heimvorteil ist einer der am besten dokumentierten Effekte im Fußball. Mannschaften gewinnen zu Hause häufiger, erzielen mehr Tore und kassieren weniger. Die Gründe dafür sind vielfältig: Vertrautheit mit dem Spielfeld, Unterstützung durch die Fans, fehlende Reisestrapazen und möglicherweise auch subtile psychologische Effekte auf die Schiedsrichterentscheidungen.
KI-Systeme berücksichtigen diesen Effekt, indem sie separate Statistiken für Heim- und Auswärtsspiele führen. Eine Mannschaft kann zu Hause ein Löwe sein und auswärts ein Lamm, und diese Asymmetrie muss in jede seriöse Prognose einfließen. In der Champions League ist dieser Effekt tendenziell etwas geringer als in nationalen Ligen, da die teilnehmenden Mannschaften durchweg hochklassig sind und professionelle Reise- und Regenerationsbedingungen haben.
Clean Sheets und defensive Stabilität
Die Anzahl der Spiele ohne Gegentor sagt viel über die defensive Organisation einer Mannschaft aus. Clean Sheets sind besonders relevant für die Prognose von Über-Unter-Wetten und für die Einschätzung, wie eng ein Spiel vermutlich verlaufen wird.
Eine defensiv stabile Mannschaft mit vielen Spielen ohne Gegentor tendiert zu niedrig torenden Partien. Treffen zwei solcher Teams aufeinander, sinkt die Wahrscheinlichkeit für spektakuläre Ergebnisse. Umgekehrt können zwei offensiv orientierte Teams mit löchriger Defensive für torreichere Partien sorgen.
Von Rohdaten zur Vorhersage: Der statistische Prozess
Die Umwandlung von Rohdaten in konkrete Vorhersagen folgt einem mehrstufigen Prozess, den moderne KI-Systeme weitgehend automatisiert durchführen.
Datenbereinigung und Validierung
Bevor Zahlen in ein Modell fließen, müssen sie auf Plausibilität geprüft werden. Fehlerhafte Daten können Prognosen verzerren, und selbst renommierte Datenanbieter sind nicht vor Fehlern gefeit. Ein Tippfehler, der einem Spieler zehn Tore statt eines zuschreibt, würde alle nachfolgenden Berechnungen verfälschen.
KI-Systeme nutzen automatisierte Plausibilitätsprüfungen, um offensichtliche Ausreißer zu identifizieren. Ein Spieler mit mehr Toren als Einsatzminuten wäre beispielsweise ein klarer Hinweis auf einen Datenfehler.
Berechnung der erwarteten Torwerte
Basierend auf den bereinigten Daten berechnet das System für jede Mannschaft einen Erwartungswert für die Anzahl der Tore. Dieser Wert berücksichtigt die eigene Angriffsstärke, die Defensivstärke des Gegners und den Heimvorteil.
Die klassische Formel multipliziert die Angriffsleistung der einen Mannschaft mit der Defensivschwäche der anderen und skaliert das Ergebnis auf ligadurchschnittliche Werte. Eine Mannschaft mit überdurchschnittlicher Angriffsstärke gegen eine mit unterdurchschnittlicher Defensive führt zu einem höheren Torerwartungswert.
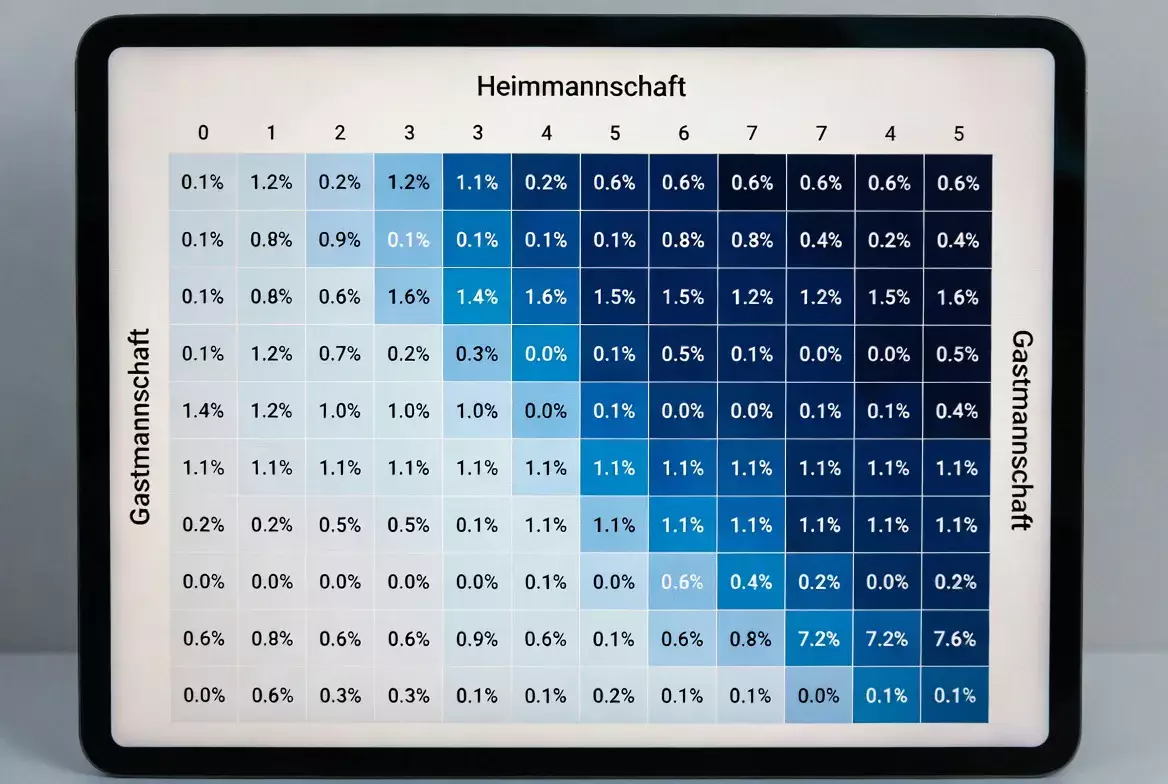
Wahrscheinlichkeitsmatrix erstellen
Mit den erwarteten Torwerten beider Mannschaften lässt sich eine Matrix aller möglichen Ergebnisse erstellen. Die Poisson-Verteilung liefert für jede Kombination aus Heim- und Auswärtstoren eine Wahrscheinlichkeit.
Diese Matrix zeigt beispielsweise, dass ein 1:0 eine Wahrscheinlichkeit von 8,5 Prozent hat, ein 2:1 eine von 11,2 Prozent und so weiter. Die Summe aller Ergebnisse mit Heimsieg ergibt die Gesamtwahrscheinlichkeit für einen Heimsieg, analog für Unentschieden und Auswärtssieg.
Kalibrierung und Anpassung
Rohe Modellvorhersagen werden in der Regel noch kalibriert, um systematische Verzerrungen zu korrigieren. Wenn ein Modell historisch dazu neigt, Unentschieden zu unterschätzen, kann eine Korrektur eingefügt werden.
Die Kalibrierung basiert auf dem Vergleich vergangener Vorhersagen mit den tatsächlichen Ergebnissen. Ein gut kalibriertes Modell sollte bei Ereignissen, denen es 60 Prozent Wahrscheinlichkeit zuweist, auch tatsächlich in etwa 60 Prozent der Fälle richtig liegen.
Statistische Fallstricke bei Fußballprognosen
Wer statistische Vorhersagen erstellt oder nutzt, sollte sich der typischen Fehlerquellen bewusst sein. Drei davon sind besonders häufig und folgenreich.
Das Problem kleiner Stichproben
In der Fußballforschung ist dieses Problem besonders akut. Eine Mannschaft in der Champions League spielt pro Saison maximal 17 Spiele, wenn sie bis ins Finale kommt. Die meisten Teams haben deutlich weniger Datenpunkte. Diese geringe Stichprobengröße macht statistische Aussagen grundsätzlich unsicherer.
Konkret bedeutet das: Wenn eine Mannschaft in sechs Champions-League-Spielen viermal zu Null gespielt hat, könnte man versucht sein, ihr eine defensive Meisterleistung zu attestieren. Doch sechs Spiele sind statistisch gesehen ein sehr kleines Sample. Die wahre defensive Qualität dieser Mannschaft könnte deutlich höher oder niedriger liegen als diese 66 Prozent Clean-Sheet-Quote suggerieren.
Forscher haben gezeigt, dass kleine Stichproben zu überschätzten Effektgrößen führen können. Ein scheinbar sensationeller statistischer Zusammenhang entpuppt sich bei größerer Datenbasis oft als weit weniger dramatisch. In der Fußballanalytik sollte man daher besonders vorsichtig sein, wenn beeindruckende Statistiken auf wenigen Spielen basieren.
Overfitting: Wenn das Modell zu schlau ist
Overfitting beschreibt das Phänomen, dass ein Modell historische Daten perfekt erklärt, aber bei neuen Daten versagt. Es hat quasi die Vergangenheit auswendig gelernt, statt allgemeingültige Muster zu erkennen.
Stellen Sie sich ein Modell vor, das jeden Torschützen der letzten Saison mit seinem individuellen Torwert berücksichtigt. Dieses Modell wird die Vergangenheit hervorragend erklären, denn es weiß ja, wer wann getroffen hat. Für Zukunftsprognosen ist es jedoch nutzlos, denn es hat nicht gelernt, welche Faktoren generell Tore begünstigen, sondern nur, wer zufällig getroffen hat.
Moderne KI-Systeme nutzen Techniken wie Kreuzvalidierung, um Overfitting zu vermeiden. Dabei wird das Modell auf einem Teil der Daten trainiert und auf einem anderen getestet, den es nie gesehen hat. Nur wenn es auch auf den Testdaten gut abschneidet, gilt das Modell als robust.
Survivorship Bias im Fußball
Dieser subtile Fehler entsteht, wenn wir nur erfolgreiche Fälle betrachten und die gescheiterten ignorieren. Im Fußball zeigt sich das beispielsweise bei der Analyse von Meistermannschaften.
Wer untersucht, was Meister auszeichnet, findet möglicherweise bestimmte Statistiken, die alle Champions gemeinsam haben. Der Fehler liegt darin, nicht zu prüfen, ob dieselben Statistiken auch bei Mannschaften auftreten, die nicht Meister wurden. Vielleicht sind die vermeintlichen Erfolgsfaktoren gar nicht so einzigartig.
Im Champions-League-Kontext bedeutet das: Wenn ein Analyst feststellt, dass alle bisherigen Finalisten einen bestimmten xG-Wert hatten, heißt das nicht, dass dieser Wert eine Voraussetzung für den Erfolg ist. Es könnte sein, dass viele Mannschaften mit ähnlichen Werten ebenfalls teilgenommen haben, aber ausgeschieden sind.
Die Aussagekraft von CL-Statistiken richtig einschätzen
Die Frage, wann statistische Daten aus der Champions League wirklich aussagekräftig sind, lässt sich nicht pauschal beantworten. Es hängt von der Art der Statistik und dem Verwendungszweck ab.
Wann sechs Spiele genug sind
Für manche Fragestellungen reichen wenige Spiele tatsächlich aus. Wenn ein Team in allen sechs Gruppenspielen den Ballbesitz klar dominiert hat, ist das ein starkes Signal für den Spielstil dieser Mannschaft. Der Ballbesitz ist eine relativ stabile Eigenschaft, die weniger von Zufallseffekten abhängt als beispielsweise die Torausbeute.
Andere Statistiken benötigen deutlich mehr Datenpunkte. Die Quote gegnerischer Torschüsse, die ins Netz gehen, hängt stark von Zufallsfaktoren ab. Sechs Spiele sagen hier wenig über die wahre Qualität der Defensive aus.
Als Faustregel gilt: Je mehr eine Statistik vom Zufall abhängt, desto größer muss die Stichprobe sein, um verlässliche Schlüsse zu ziehen. Ballbesitz und Passquote stabilisieren sich schneller als Tore und Expected Goals.
Saisonübergreifende Trends versus aktuelle Form
Ein ewiges Dilemma der Fußballstatistik ist die Frage, wie weit die Vergangenheit in die Analyse einbezogen werden sollte. Einerseits liefern mehr Daten stabilere Schätzungen. Andererseits verändern sich Mannschaften durch Transfers, Trainerwechsel und taktische Anpassungen.
Die optimale Lösung liegt in der differenzierten Betrachtung. Für strukturelle Eigenschaften wie Spielstil oder taktische Grundausrichtung können auch ältere Daten wertvoll sein, sofern der Trainer derselbe geblieben ist. Für leistungsbezogene Metriken sollten jüngere Daten stärker gewichtet werden, da sie den aktuellen Zustand besser widerspiegeln.
KI-Systeme lösen dieses Problem oft durch adaptive Gewichtung, bei der der Einfluss älterer Daten exponentiell abnimmt. Die Halbwertszeit, also die Zeit, nach der ein Spiel nur noch halb so viel zählt wie ein aktuelles, liegt typischerweise bei einigen Monaten.
Champions League versus nationale Liga
Statistiken aus der nationalen Liga und der Champions League sollten nicht unreflektiert gemischt werden. Die Gegnerqualität unterscheidet sich fundamental. Ein Team, das in der heimischen Liga dominiert, trifft in der Königsklasse auf annähernd gleichwertige Gegner.
Die Konsequenz für Prognosen: Champions-League-Statistiken haben für Champions-League-Vorhersagen grundsätzlich mehr Aussagekraft als Ligadaten, sofern genügend Spiele vorliegen. Umgekehrt können Ligadaten helfen, das Bild zu vervollständigen, wenn die europäische Datenbasis zu dünn ist.
Erfahrene Analysten nutzen beide Quellen, gewichten aber die CL-Daten höher, wenn es um spezifische Prognosen für Europapokalspiele geht.
Die Rolle des Zufalls in der Champions League
Ein Aspekt, der in der statistischen Diskussion oft untergeht, ist die fundamentale Rolle des Zufalls im Fußball. Wissenschaftliche Untersuchungen haben gezeigt, dass über 70 Prozent der Varianz in der Punkteverteilung der Bundesliga durch Zufall erklärt werden können. In der Champions League, wo weniger Spiele und höhere Gegnerqualität aufeinandertreffen, dürfte dieser Anteil noch höher liegen.
Warum der Zufall so dominiert
Fußball ist ein Spiel mit wenigen Toren. Im Durchschnitt fallen pro Partie etwa 2,6 Treffer, was bedeutet, dass einzelne Ereignisse enormes Gewicht haben. Ein Tor, das in der Nachspielzeit fällt, kann eine komplette Statistiksaison verzerren. Ein Pfostentreffer in der 89. Minute entscheidet darüber, ob ein Team als Überperformer oder als Enttäuschung gilt.
Dieser Zusammenhang erklärt auch, warum die Trefferquote selbst der besten Prognosemodelle bei etwa 55 Prozent liegt. Es ist schlicht unmöglich, Ereignisse vorherzusagen, die von Millimeterdifferenzen abhängen. Der Ball, der knapp am Tor vorbeigeht, unterscheidet sich physikalisch kaum von dem, der im Netz landet. Statistisch gesehen sind beide Ereignisse Teil derselben Zufallsverteilung.
Umgang mit Unsicherheit
Die Konsequenz für jeden, der sich mit statistischen Prognosen beschäftigt, ist klar: Unsicherheit ist kein Bug, sondern ein Feature. Ein gutes Modell versucht nicht, Unsicherheit zu eliminieren, sondern sie ehrlich zu quantifizieren.
Wenn eine KI-Vorhersage einem Team 65 Prozent Siegchance gibt, bedeutet das gleichzeitig, dass in 35 Prozent aller Fälle etwas anderes passiert. Diese 35 Prozent sind nicht das Versagen des Modells, sondern die korrekte Abbildung der Realität. Fußball wäre langweilig, wenn der Favorit immer gewänne.
Die Champions League lebt von ihren Überraschungen. Das Wunder von Istanbul 2005, als Liverpool einen 0:3-Rückstand gegen Milan aufholte, wäre in keinem Statistikmodell vorhergesagt worden. Und doch war es statistisch gesehen möglich, nur eben sehr unwahrscheinlich. Solche Momente erinnern uns daran, dass Wahrscheinlichkeit nicht Gewissheit bedeutet.
Vergleich verschiedener statistischer Ansätze
Die Landschaft der Fußballvorhersagen ist vielfältig. Verschiedene Anbieter und Modelle nutzen unterschiedliche methodische Ansätze, die jeweils eigene Stärken und Schwächen haben.
Elo-basierte Systeme
Das Elo-System, ursprünglich für Schachspielerbewertungen entwickelt, hat sich im Fußball als robuste Methode etabliert. Es weist jedem Team einen Zahlenwert zu, der die relative Spielstärke repräsentiert. Nach jedem Spiel werden die Werte angepasst: Der Sieger gewinnt Punkte, der Verlierer verliert sie, wobei die Höhe der Anpassung von der vorherigen Einschätzung abhängt.
Der Vorteil von Elo-Systemen liegt in ihrer Einfachheit und Robustheit. Sie neigen nicht zu Overfitting, weil sie nur eine Variable pro Team verwenden. Der Nachteil ist, dass sie keine taktischen oder spielerischen Nuancen erfassen. Zwei Teams mit demselben Elo-Rating können sehr unterschiedlich spielen.
Expected-Goals-basierte Modelle
Ein modernerer Ansatz stützt sich auf Expected Goals, also die statistisch erwartete Torzahl basierend auf der Qualität der Torchancen. Diese Modelle argumentieren, dass die tatsächlich erzielten Tore durch Zufall verzerrt sein können. Ein Team, das konstant gute Chancen kreiert, aber Pech beim Abschluss hat, sollte höher eingeschätzt werden als sein Punktekonto vermuten lässt.
Der Vorteil dieses Ansatzes ist die höhere Granularität. Er unterscheidet zwischen Teams, die viele Chancen kreieren, und solchen, die wenige hochwertige Gelegenheiten herausspielen. Der Nachteil liegt in der Abhängigkeit von der Qualität der xG-Daten und der Annahme, dass xG-Überperformance nicht nachhaltig sein kann.
Hybride Ansätze
Die meisten modernen Prognosemodelle kombinieren verschiedene Informationsquellen. Sie nutzen Elo-artige Ratings für die Grundeinschätzung, verfeinern diese mit xG-Daten und berücksichtigen situative Faktoren wie Heimvorteil, Verletzungen und Spielbelastung.
Diese Kombination erfordert sorgfältige Gewichtung. Wie stark soll xG gegenüber tatsächlichen Toren gewichtet werden? Wie schnell sollen sich Ratings nach überraschenden Ergebnissen anpassen? Diese Fragen haben keine objektiv richtigen Antworten, sondern erfordern empirische Kalibrierung.
Praktische Tipps für den Umgang mit statistischen Prognosen
Wer KI-gestützte Vorhersagen für die Champions League nutzen möchte, sollte einige Grundregeln beherzigen.
Erstens: Hinterfragen Sie die Datenbasis. Wie viele Spiele fließen in die Prognose ein? Werden Heim- und Auswärtsspiele unterschieden? Wie alt sind die Daten? Transparente Anbieter kommunizieren diese Informationen offen.
Zweitens: Verstehen Sie Wahrscheinlichkeiten als das, was sie sind. Eine 70-Prozent-Prognose für einen Sieg bedeutet auch 30 Prozent Chance auf ein anderes Ergebnis. Drei von zehn Fällen enden anders als vorhergesagt, und das ist völlig normal.
Drittens: Seien Sie skeptisch gegenüber extremen Aussagen. Wenn eine Plattform behauptet, 90 Prozent der Champions-League-Spiele richtig vorherzusagen, stimmt etwas nicht. Selbst die besten Modelle erreichen solche Trefferquoten nicht, weil der Fußball zu viel Zufall enthält.
Die Statistik ist ein mächtiges Werkzeug für Fußballvorhersagen, aber sie hat Grenzen. Diese Grenzen zu kennen und zu respektieren unterscheidet fundierte Analyse von blindem Zahlenglauben. Die Champions League bleibt auch mit den besten Algorithmen ein Wettbewerb voller Überraschungen, und vielleicht ist das auch gut so.
Die Zukunft statistischer Fußballprognosen
Der Bereich der Fußballstatistik entwickelt sich rasant weiter. Neue Datenquellen, verbesserte Algorithmen und steigende Rechenleistung versprechen noch präzisere Vorhersagen in der Zukunft.
Tracking-Daten als nächste Frontier
Die nächste Revolution in der Fußballstatistik kommt von Tracking-Daten. Moderne Stadien erfassen jede Spielerbewegung bis zu 25 Mal pro Sekunde. Diese Fülle an Informationen ermöglicht Analysen, die weit über traditionelle Statistiken hinausgehen.
Anstatt nur zu wissen, dass ein Team 55 Prozent Ballbesitz hatte, können Analysten nun verstehen, wie dieser Besitz gestaltet wurde. Wurde in gefährlichen Zonen gespielt oder nur quer über den Platz? Wie schnell wurden Umschaltmomente eingeleitet? Wie intelligent positionierten sich Spieler ohne Ball?
Für Prognosemodelle bedeutet das eine erhebliche Verfeinerung. Statt Teams als homogene Einheiten zu behandeln, können Modelle lernen, welche Spielkonstellationen besonders gefährlich sind und welche taktischen Anpassungen Spiele drehen können.
Die Grenzen werden bleiben
Trotz aller Fortschritte werden statistische Modelle niemals perfekte Vorhersagen liefern können. Der Grund dafür liegt nicht in technischen Limitationen, sondern in der Natur des Fußballs selbst.
Jedes Spiel enthält Elemente, die sich jeder Quantifizierung entziehen. Die Nervenstärke eines Spielers in einem entscheidenden Moment. Die chemische Veränderung, wenn ein Stadion zum Hexenkessel wird. Der Instinkt eines Trainers, der zur Halbzeit genau die richtige Anpassung trifft. Diese menschlichen Faktoren sind statistisch nicht erfassbar und werden es vermutlich nie sein.
Die Anerkennung dieser Grenzen ist kein Eingeständnis des Scheiterns, sondern ein Zeichen von wissenschaftlicher Reife. Die besten Analysten sind diejenigen, die wissen, was ihre Modelle leisten können und was nicht. Sie nutzen Statistik als ein Werkzeug unter vielen, nicht als alleinige Wahrheit.
Für Fans der Champions League bedeutet das: Genießen Sie die Spannung des Wettbewerbs. Nutzen Sie statistische Prognosen als interessante Perspektive, nicht als Spoiler. Und freuen Sie sich auf die Überraschungen, die selbst die beste KI nicht kommen sieht. Denn genau darin liegt der Zauber des Fußballs, der alle Algorithmen der Welt nicht einfangen können.